こちらの記事を拝見しました。
こちらで紹介されている論文が、結構きれいまとめられているように見えたので、この論文を読んだメモを書いてみたいと思います。
tl;dr;
- いろんな意味で、DNNの効率は大事
- 効率を考える上で、考慮すべきことの枠組みを作った
論文
著者
GAURAV MENGHANI (Google Research, USA)
背景
この10年ほどで、DNNは画像やNLPで著しい成果を出してきました。 一方、パラメータ数も増大しており、実社会のアプリケーションにDNNを入れることはより大変になってきているのも事実かと思います。
パラメータの増大に伴う複雑性によって高い成果を上げてきたDNNではあるが、それを実社会に適用する際には、大きく下記のような点で苦労すると考えているようです。
- サーバーサイドでの継続的なスケーリング
- デバイスへのモデル配信
- プライバシーやデータ管理
- 新しいアプリケーションへの適用の難しさ
- モデル数の増大によるリソースの枯渇
この辺りを解決することが、多くのエンジニアに求められていることと予想されます。 そして、これらに共通して言えることは効率が重要ということで、効率を下記のように定義しています。
- 推論
- 学習
これらの効率を向上させることが上で上げた問題を解決することにつながると考えるのが、このモチベーションだと理解しています。
メンタルモデル
論文中で紹介されている「メンタルモデル」は下記のように示されています。
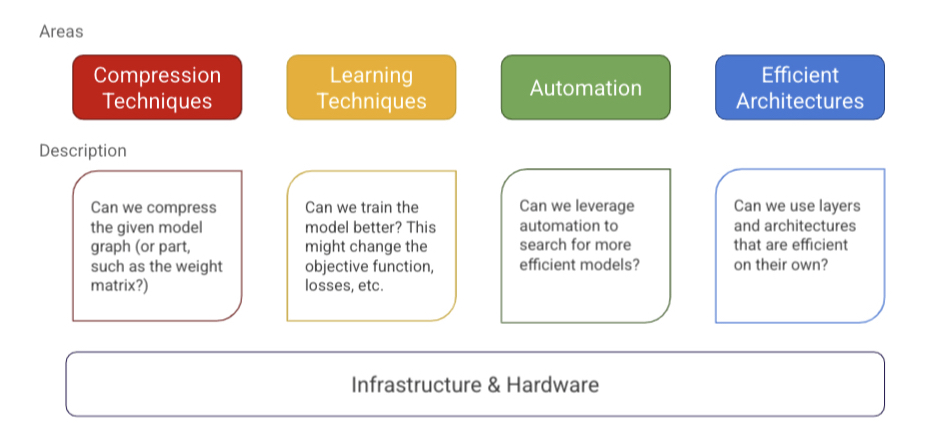
個人的解釈として、「こういう枠組みで考えるとスッキリ整理できるよ」というものだと理解。 要素としては5つあって、
- モデルの圧縮
- 学習テクニック
- 自動化
- 効率的アーキテクチャ
- インフラ
と考えるようです。
この辺を工夫しつつ、精度指標と他のメトリクスの間のトレードオフを調整するサイクルを回すことで、効率良いモデルを作っていくことを目的としているようです。
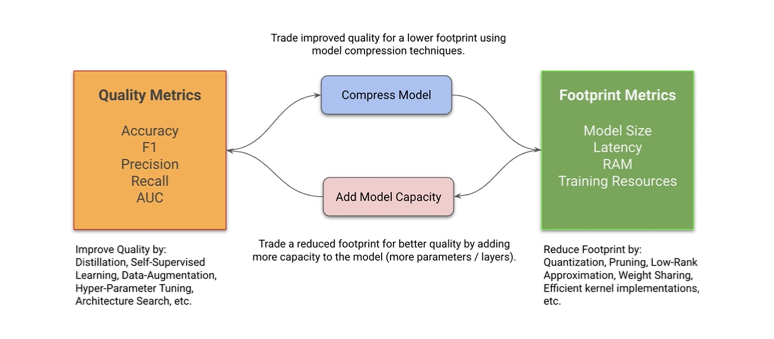
要素整理
ここから先はそれぞれの要素についての概要だけ確認します。 最新の状況は記載と違うこともあるかと思うので、その分野の論文を確認することをおすすめします。
モデル圧縮
これまでにもモデル圧縮に関しては研究が進められていますね。
Pruning
ニューラルネットワークにおいて、結合要素の刈り込みを行うことをPruningと呼ばれます。
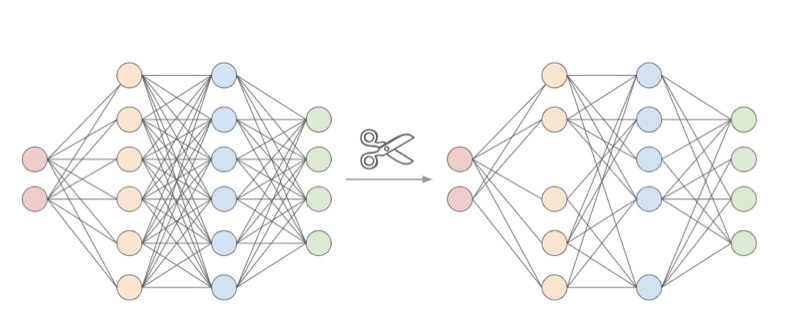
通常、学習済みのネットワークについてモデルの品質が過度に低下しないことを確認しつつ重要度(saliency)の低そうな結合を切り落としていき、最後にPruningしたネットワークを微調整することで実現するようです。
これにより、モデルサイズは小さくすることができます。
Quantization
通常、DNNでは変数は32bitのfloatが使用されるかと思います。 「これ、本当に32bitも必要ですか?もっと荒くできますよね?」って考えを推し進めたのがQuantizationの考え方ですかね。(暴論)
変数の精度を小さくすることで、
- データ量としてモデルを小さくできる
- 処理時間としても小さくできる
といったメリットがあります。
数学演算を浮動小数点から固定小数点へ置き換えるなどのテクニックを使うと、量子化を解除しなくて良くなったりするので更に効率が良くなったりするとかしないとか。さらに、量子化すると当然モデルは不安定になるので、学習時に量子化を考慮して工夫した学習をするみたいです。(この辺いまいちピンときてない)
学習テクニック
Distillation (蒸留)
小さいモデルを使用すれば、それだけモデルの効率は良くなります。 ただ、大きなモデルほど精度が高くなる傾向もあります。
そこで、大きなモデルの知識を小さなモデルに適用するやり方をDistillationと呼んだりします。 概念としては、本来の学習データのラベルに加えて大きなモデル(Teacher Network)によるラベルごとの推論確率の分布を加えて小さなモデル(Student Network) を学習するというやり方ですね。
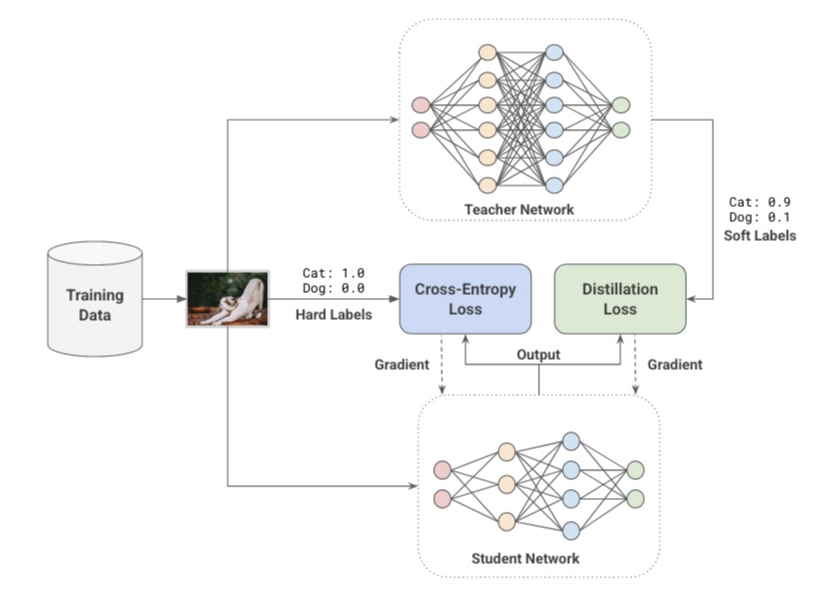
Data Augmentation (データ拡張)
モデルの精度とラベル付きのデータの数は相関すると考えられますが、ラベル付きのデータを用意するのに苦労することもよくあります。 そういった場合に、データを増強することをData Augmentationと呼ばれます。
具体的には、ラベルは変化させずに切り抜いたり(Cutout)やブレンド(Mixup)したりする方法、複数のラベルのデータを混ぜ合わせる方法、それらを組み合わせる方法など、色々あるようです。へえ。
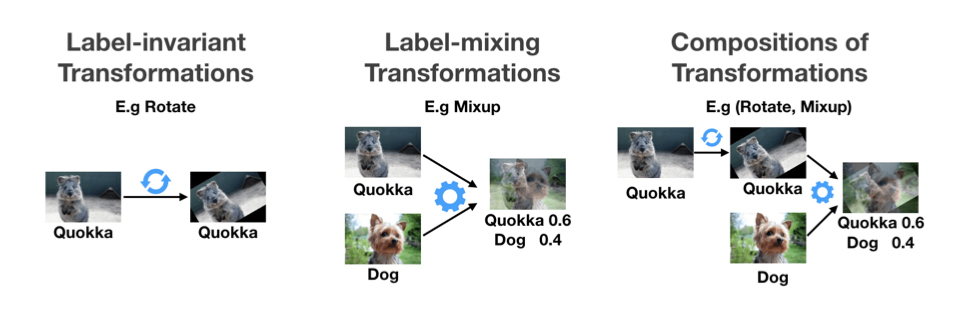
その他、半教師あり学習も紹介されていました。
自動化
モデル学習の効率化のために、パラメータの一部を自動で探索することが有効なことがあります。
Hyper-Parameter Optimization(HPO)
この手の話でよく出てくるのはハイパーパラメータの探索かと思います。
よく使われる手法としては、
- Grid Search
- Bayesian Optimization
かなとは思います。 (一応論文中ではRandom Searchも紹介していますが、あまりやってる人見たことないのでメジャーではないと思ってます。)
そのほかPBT(Population Based Training)やSHA(Successive Having)なども紹介されており、上記のやり方で問題がありそうなときはこの辺を検討してみるのも良いかもしれませんね。
Neural Architecture Search
その他、NNの構造も、見方によってはパラメータによって決定されていると考えられます。 探索空間・探索のアルゴリズムを決め、評価しながら探索するようです。
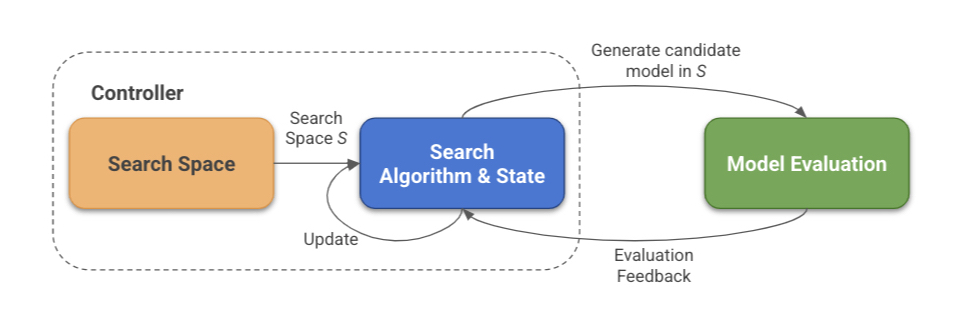
一応こういう世界もあるということは覚えておきたいと思います。
効率的アーキテクチャ
ConvolutionやらAttentionなどのテクニック(仕組み?)が紹介されています。今回は省略。
インフラ
アプリケーションレベルでのテクニックも重要ではありますが、効率を考える上でインフラも重要になります。 ソフトウェア・ハードウェアの両方の観点で、インフラを考える必要があるかと思います。
- TensorFlowやPyTorchのエコシステムが便利
- 低レイヤの高速化ライブラリも使えるなら選択肢になる
- その他GPUやTPUもあるのでそのへんを活用してサーバーサイドでの効率をあげられる
ってことだと理解。 読んでて力尽きたので、最後の方は省略。
感想
体系的に整理されている感じがしたので読んでみた次第です。 いろいろテクニックもわかりやすい図と一緒に紹介されていて、個人的に知らないテクニックもあったので非常に勉強になりました。