タイトルの論文を読んでみたので、内容に関する雑なメモです。
tl;dr;
- Twitterでは、推薦機能はいろいろなところに使用されており、アイテムのライフサイクルなどが異なる
- これまで個別に機能を開発していたものを、共通して使用できる基盤を整備したかった
- SimClusters
- 処理全体を2段階に分ける
- 1段階目: user-userのグラフから、所属するコミュニティを計算する
- 2段階目: 所属コミュニティを使用して、個別の推薦の計算
- 所属するコミュニティを計算するを計算する処理が共通化することができた
- 処理全体を2段階に分ける
論文
https://dl.acm.org/doi/10.1145/3394486.3403370
著者
Venu Satuluri, Yao Wu, Xun Zheng, Yilei Qian, Brian Wichers, Qieyun Dai, Gui Ming Tang, Jerry Jiang, Jimmy Lin
背景
Twitterのサービスでは、多くの推薦が使用されています。 Home画面のツイートの表示や、フォローするユーザーの表示、トレンドになっているハッシュタグなど、使用場面や推薦のライフサイクルも様々になっています。
過去には、これらの推薦は個別にシステムを構築しており、共通化が進んでいませんでした。 そのままだと、システムのメンテナンスコストが大きくなってしまいます。
目的
- パーソナライズやレコメンドが必要な場面の多くで有用な共通基盤を構築する
SimClusters
SimClustersは下記のように大きく2つの段階に別れています。
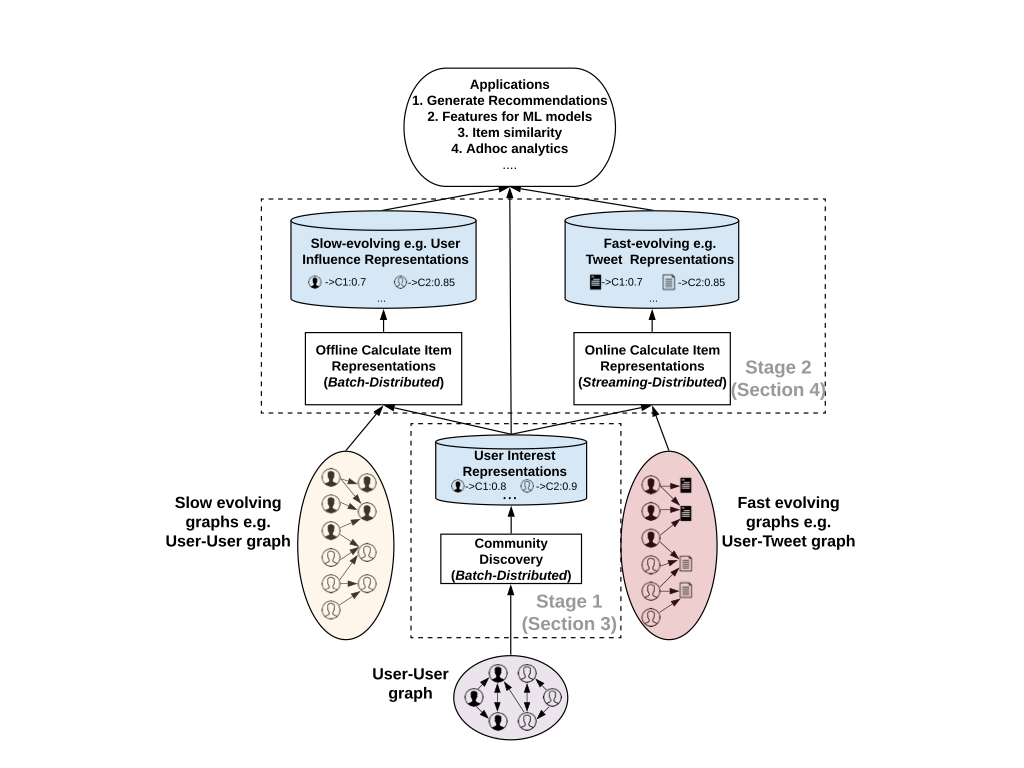
- Community Discovery
- user-userのグラフを元に所属するコミュニティを発見し、ユーザーが各コミュニティにどの程度所属しているかを算出
- Item Representations
- インタラクションを元に作成されたuser-targetのグラフを使用して推薦するアイテムの表現を算出
この2つが分離されていて、それらがオフラインのデータセットやオンラインのKVSを介して連結されていることにより、共通の推薦基盤を実装するうえでは可用性や拡張性の点で利点があるそうです。
Community Discovery
Community Discoveryの流れとしては、下記の図のような流れで行われるようです。
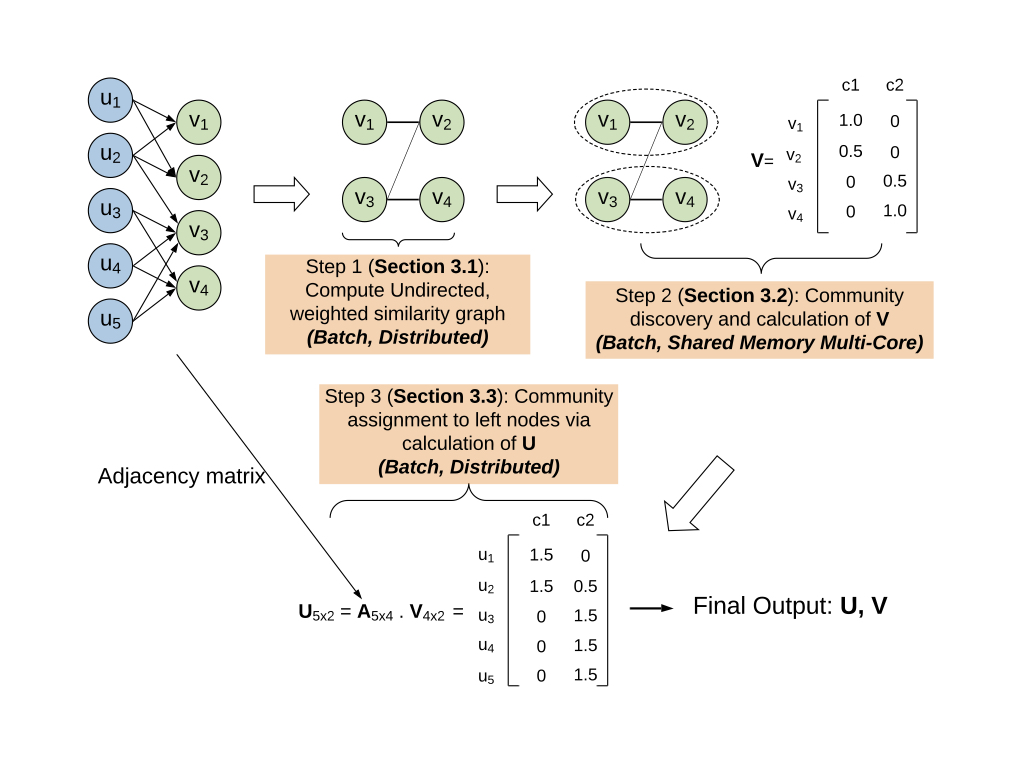
このとき、user-userのつながりを表すグラフについて、フォロワー数が一定以上のユーザー(〜)を右側、それ以外のユーザー(〜
)を左側としているようで、その間をまたがるつながりは〜
のスケールになり、基本的に右側のグループが小さくなることが前提となっています。
Step1: 右側のノード群で類似性の無向グラフを作成
ここでは右側のノード群の中でそれぞれの間での類似性を表す無向グラフを作ることを考えます。
類似性は、二人のユーザーについてそれぞれのフォロワー(おそらくサイズは)のベクトルの内積を取ることで得ることができます。
得られた類似性について、一定のしきい値を越えたものかつそれぞれのユーザーについて結合が一定数未満になるように調整することで、無向グラフを得ることができます。
Step2: 右側のノード群からコミュニティを識別
次に、得られた無向グラフから、右側の各ユーザーがどのコミュニティに属しているかを識別することを考えます。
おそらくここで前提となることは、上で求めた無向グラフより、「類似性の結合を持つユーザーは、結合するユーザーと著しく異なるコミュニティに属することは稀である」という考えがあるようです。 そのため、グラフ上で隣接するユーザーだけに着目して所属するコミュニティを判断すれば良さそうです。
このことを念頭にユーザーがどのコミュニティに所属するかを評価する目的関数は下記のようにされています。
この解釈としては、
- 隣接するユーザー間で一つ以上の共通するコミュニティがあるペアの数
- 隣接しないユーザー間で共通するコミュニティが0であるペアの数
の和になっており、これが最大化することが「所属するコミュニティの良い推定」だと考えられます。
これについて、コミュニティを推定する方法を考えます。 下記のような状況で、Aのコミュニティの所属を更新することを考えます。
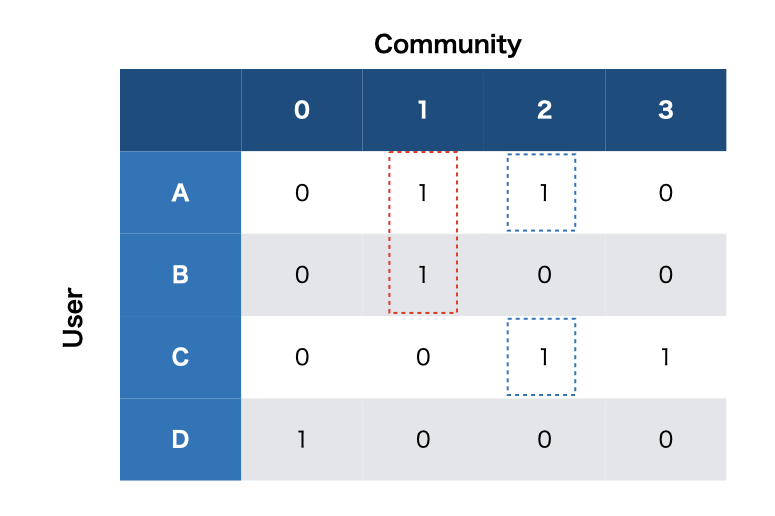
このとき、ユーザーAとBとCが類似しているとします。 このときBが所属していると考えられるコミュニティ1とCが所属していると考えられるコミュニティ2のフラグ候補を立て、このときの目的関数の値を算出します。
次にこの評価値を使用して部分集合について、この更新を採用するかどうかをサンプリングします。 これをすべてのユーザーについて何度も繰り返すことで、目的関数が最大化するように進めていくようです。
Step3: 左側のノード群にコミュニティを適用
Step2までで、右側のユーザーがどのコミュニティに所属するかは求めることができました。 これを左側のユーザーに対しても適用します。
右側のユーザーは左側のユーザーからフォローの関係があると考えられ、この隣接行列をA、Step2で求めたユーザー-コミュニティの隣接行列をVとすると
で計算することができます。 ここで、 ユーザーが一定以上のコミュニティに所属しすぎないように、truncateでは所属するコミュニティ数にしきい値を適用しています。
以上のステップにより、user-userのグラフを元に所属するコミュニティを発見していきます。
Item Representations
次に、推薦するアイテム側を考えます。 これは、アイテムに関与したすべてのユーザーのベクトルの指数的時間減衰平均に基づいて計算します。 特に興味関心の時間的な移り変わりが速いものもあるため、時間方向の減衰係数を使用しているようです。
これにより、2つのことを考えます。 一つはアイテムに関するtop-kのコミュニティを保持します。 もう一つは、コミュニティに関してtop-kのアイテムを保持します。
このとき、アイテムの消費期限が短いものについて、現在の平均値と更新された最新の値がわかれば、それらに関する減衰係数を算出することでランクを更新することができます。
実際には
実際にはステージ2では大きく4種類のジョブが運用されているようで、
- ユーザーの影響度
- トピック
- ツイート
- トレンド
を数値評価することで、推薦に利用しているようです。 top-kの情報をKVSに保存しておき、上記4つの表現については転置インデックスを保持しておくことで推薦を実現しているようです。
評価
評価に関しては、箇条書きで…
- メール・プッシュ通知
- 25%のエンゲージメント向上
- ホーム画面でのフォロー以外のツイート
- 1%のエンゲージメント向上
- トレンドのコンテンツ表示
- 8%のエンゲージメント向上
- おすすめユーザー表示
- フォロー率が7%向上
こんな感じですね。すごいですね。
感想
直接的に観測できないコミュニティに所属しているという考えは面白いなと思いました。 ユーザーのコミュニティへの所属に基づいて、後続の個別の推薦のジョブが走っているイメージですかね。
これだけの規模になると並列処理ができるかどうかも重要なポイントで、またアイテムのライフサイクルも異なります。 並列処理できるようにするだけでなく、中間のデータ(この場合で言えばユーザーのコミュニティへの所属関係)を様々なところで活用することで有効活用しているのは面白いなと思いました。