
複数の時系列データがあるとき、これらを傾向に従ってクラスタリングしたくなることがあります。 そういった手法を、時系列クラスタリングと呼ぶらしいです。
ちょっと調べてみると、こちらの記事を見かけました。
時系列クラスタリングの研究サーベイ論文を読んだ | 10001 ideas
こちらの記事を参考に、時系列クラスタリングにをやってみたので、今回はそのメモです。
時系列クラスタリング
時系列データを、いくつかのグループに分類することを時系列クラスタリングと言います。 普通のクラスタリングと大きく異なる点として、時系列でなければ各データに紐づく特徴量を元にクラスタリングしますが、時系列クラスタリングでは時間方向に関する系列値の変化がクラスタリングを行う上で大きな情報になる点が挙げられます。
時系列クラスタリングの分類
一口に時系列クラスタリングと言っても、その中には種類があるようです。
ほとんどの時系列クラスタリングは3カテゴリーに分類できる。一つ目は Whole time-series clustering。これは個別の時系列データに対してのクラスタリング。二つ目は Subsequence clustering。単一の時系列からスライディングウィンドウなどにより部分系列を複数取り出して、クラスタリングするカテゴリー。三つ目は Time point clustering。これは時間的な近さと値の関係をもとにしてクラスタリングするパターン。 時系列クラスタリングの研究サーベイ論文を読んだ | 10001 ideas
ざっくりと、
- 個別の系列全体を取り扱うもの
- それぞれの系列を更に細かく分割して取り扱うもの
- 系列に関するドメイン知識を使用するもの
といったものがあるようです。
類似性の着眼点
何に基づいて分類するかを見ていきます。
こちらは大きく3つに分けられるようで、
- 各時刻における系列値
- 系列の形状
- 系列の変化の特徴
があるそうです。 この辺りが、時系列クラスタリングの特徴的な部分かと思います。
手法
大体6種類くらいあるようです。
- 階層クラスタリング
- Partitioning clustering
- Model-based clustering
- Density-based clustering
- Grid-based clustering
- Multi-step clustering
この辺は、「へー、そんなんあるんだ」と言う感じですね。
やってみる
理屈だけ見てても感覚があまりわからないので、適当にやってみたいと思います。
階層クラスタリング(R)
データを作る
本当はちょっと使いたいオープンデータがあったんですが、若干センシティブな内容になってしまうので、今回は自分で系列値を生成したいと思います。
こちらの記事を参考に、データを作ってみます。
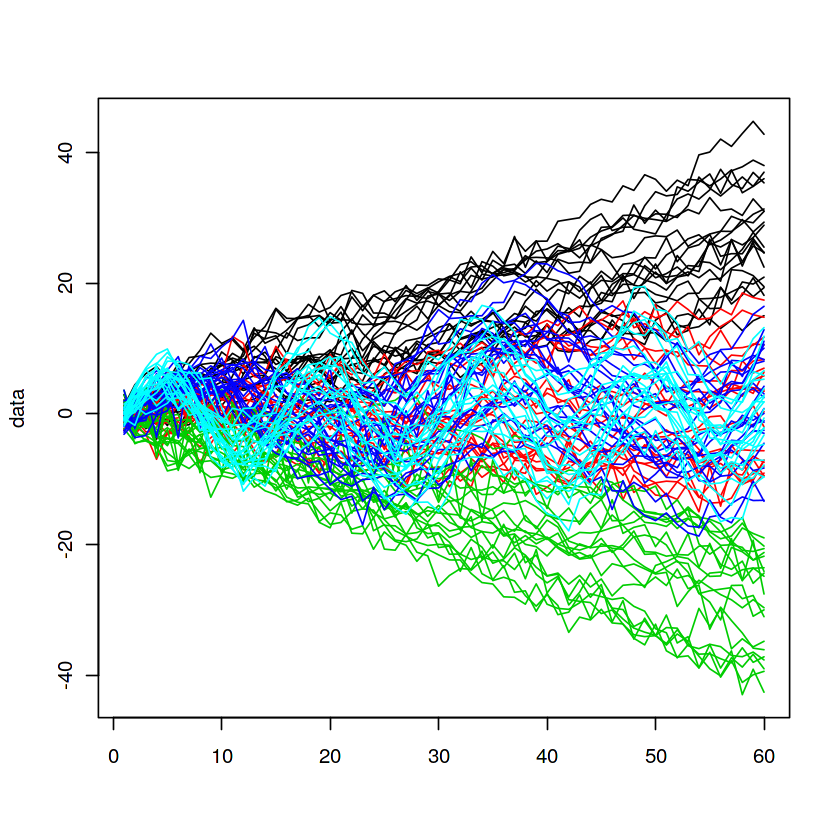
generate_ts <- function(m, label) { library(dplyr) # ランダムな AR 成分を追加 .add.ar <- function(x) { x + arima.sim(n = SPAN, list(ar = runif(2, -0.5, 0.5))) } # 平均が偏った 乱数を cumsum してトレンドとする d <- matrix(rnorm(SPAN * N, mean = m, sd = 1), ncol = N) %>% data.frame() %>% cumsum() d <- apply(d, 2, .add.ar) %>% data.frame() colnames(d) <- paste0(label, seq(1, N)) d } set.seed(101) group1 <- generate_ts(TREND, label = 'U') set.seed(102) group2 <- generate_ts(0, label = 'N') set.seed(103) group3 <- generate_ts(-TREND, label = 'D') set.seed(104) group4 <- generate_ts(0, label = 'S1_') group4 <- group4 + 5*sin(seq(0, 4*pi, length.out = SPAN)) set.seed(105) group5 <- generate_ts(0, label = 'S2_') group5 <- group5 + 5*sin(seq(0, 8*pi, length.out = SPAN)) data <- cbind(group1, group2, group3, group4, group5) data <- as.data.frame(data)
するとこんな感じに、上昇トレンド・平均回帰・下降トレンド・季節調整あり(周期が異なる2パターン)の5種類のデータが作成されているかと思います。
階層化クラスタリング
作成したデータを使用して、こちらの記事を参考に階層化クラスタリングによってクラスタリングしてみます。
やってみるとこんな感じで分類されます。
install.packages('TSclust') library(TSclust) # DTW 距離で距離行列を作成 d <- diss(data, "DTWARP") # hclust は既定で実行 = 最遠隣法 h <- hclust(d) par(cex=0.6) plot(h, hang = -1)
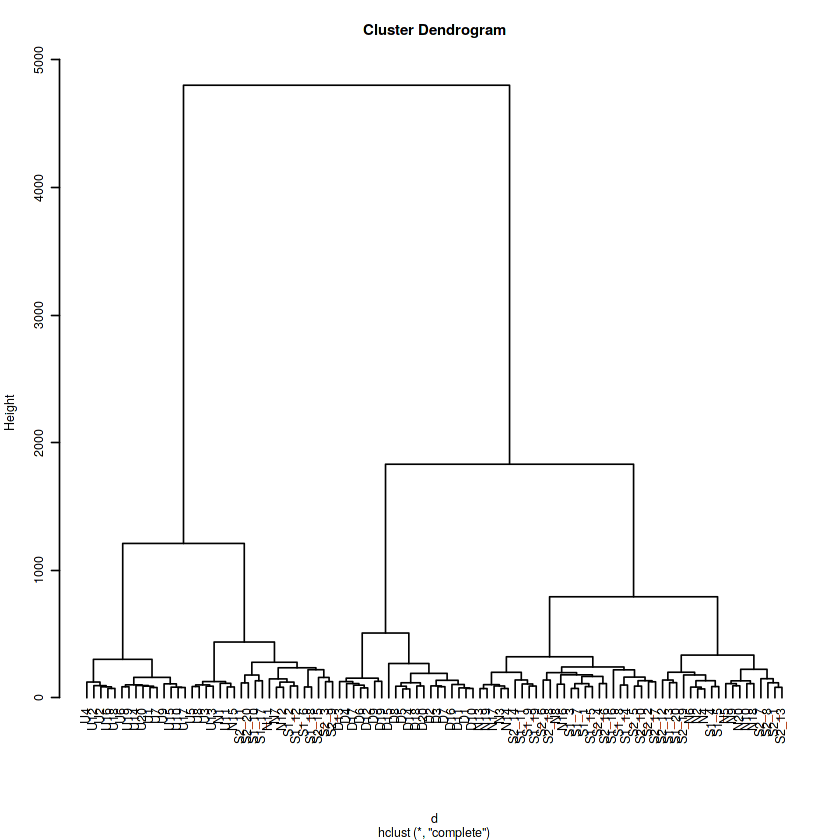
人工的に作ったデータなので、それぞれの系列にラベルが付けられるので、分類がどの程度妥当なのかを確認することができるそうなのでやってみます。
# クラスタ数は 5 とする clusters <- cutree(h, 5) # 正分類率の算出 cluster.evaluation(rep(c(1, 2, 3, 4, 5), rep(N, 5)), clusters) # 0.620856489048709
データの系列長を長くしているので、単純比較はできませんが、参考文献を眺める限り、0.5台・0.4台のスコアも出ているようなので、悪くはなさそうです。
k-means(Python)
こんどはPythonでやってみます。 別にRでやってもいいんですが、一応Pythonでなんか触ることもあると思うので。
データは上のRで作ったやつをそのまま使います。
Pythonではtslearnというライブラリが使われるようで、こちらを使ってk-meansを使ったクラスタリングをやってみます。
こちらも教師なし分類はできた気がします。
上のRでやった階層化クラスタリングと同様に評価してみます。
py <- c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 1, 1, 1, 3, 1, 1, 1, 0, 3, 3, 3, 0, 1, 3, 1, 3, 1, 2, 4, 4, 2, 4, 2, 4, 4, 2, 2, 2, 2, 2, 4, 4, 4, 2, 4, 2, 4, 1, 0, 1, 1, 1, 0, 1, 3, 3, 3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 1, 1, 3, 3, 1, 1, 3, 1, 1, 3, 1, 3, 1, 1, 3, 3, 3, 3, 3, 1, 3) # 正分類率の算出 cluster.evaluation(rep(c(1, 2, 3, 4, 5), rep(N, 5)), py) # 0.577659469584935
若干、階層化クラスタリングのほうが良さそうな感じになっています。 k-meansなのに条件固定してないので、毎回結果が変わるため参考値程度の扱いです。
正直、クラスタリングの方法やデータセット、類似性の捉え方にも依存するとは思うので、妥当な評価とは言えないと思ってます。 まあでも一応、時系列クラスタリングっぽいことはできたので良しとします。
書いたコードとか
参考文献
下記の記事を参考にさせていただきました。
時系列クラスタリングの研究サーベイ論文を読んだ | 10001 ideas
感想
時系列データを取り扱うときに、安易に「サクッとクラスタリングしよう」とか言ってしまったがために、調べる羽目になってやった次第です。
あんまり知識が無いと、結構ハマりそうだと思ったので、使いそうになったらもうちょっとちゃんと勉強しようと思います。(やるとは言ってない)