
先日、Twitterの推薦アルゴリズムがGitHubで公開されました。
Twitter recommendation source code now available to all on GitHub https://t.co/9ozsyZANwa
— Elon Musk (@elonmusk) 2023年3月31日
Twitter上で非常に盛り上がっており、すでにいろんな方がアルゴリズムに対して解説されています。 個人的にも興味深いと思っているので、何番煎じかわかりませんが自分も備忘録を書いていきたいと思います。
全体像
今回の公開されたアルゴリズムは、「For you (あなたへのおすすめ)」に表示されるアルゴリズムになっています。

全体の構成
まずは全体の流れを確認していきたいと思います。 推薦全体の大まかな流れは下記のようになっているようです。

おおよそ、下記の2段階の処理に分けられそうで、これらの処理が行われた結果おすすめが選定されているようです。
- データ取得〜特徴量作成
- 候補集合作成〜Feed作成
データ取得〜特徴量作成
使用するデータについては主に下記の3点が挙げられています。
- Social graph
- Tweet engagement
- User data
これらのデータを使用して、6種類のコンポーネントでFeatureを作成しており、これらを使用して実際の推薦を行っているようです。
- GraphJet
- 後述
- SimClusters
- 後述
- TwHIN
- 後述
- RealGraph
- 後述
- TweepCred
- Twitter内でのユーザーの評判を計算するためのPage-Rank
- Trust & Safety (T&S)
- Not safe for workなど、有害コンテンツであるかどうかに関する判定
これらによって生成された特徴量がHome Mixerに送られます。
候補集合作成〜Feed作成 (Home Mixer)
実際のHome画面に表示している要素を決める処理は、Home Mixerというコンポーネントが役割を担っているようです。
ブログを見る限り、Twitterの推薦でも一般的 (?) な推薦と同様、two stage recommendationが行われているようです。 主な動作としては、下記の3step (Mixing and Servingを入れると4step) からなっているようです。
- Candidate Sourcing (1st stage)
- 様々なアルゴリズムで選定された実際に推薦する候補ツイートを収集
- Raking (2nd stage)
- 収集した候補ツイートを良さそうな順に並べ替え
- Heuristics & Filtering
- ブロックしたユーザーのツイート、あまり良くないコンテンツ、すでに見たツイートを除外するなど
Candidate Sourcing
Candidate Sourcingでは、各ユーザーに対して1500件の「おすすめ候補」のTweetが選定されます。
Candidate Sourcingでは、自分がFollowしているところから(InNetwork)とFollowしている外(Out-of-Network Sources)からの両方から推薦候補を選定しています。 これらは、それぞれおおよそ50%ずつ取得しているようです。
※細かいアルゴリズムはあとから見ていきます。
Ranking
Candidate Sourceで選択された1500件の「おすすめ候補」のTweetについて、2段階目の関連性の推定が行われ、ランク付けが行われます。
このランキングでは何千もの特徴量を用いて、10個のラベル(個別のエンゲージメントごとの確率)を出力して各ツイートにスコアを付けし、このスコアからツイートのランク付けを行っているようです。
Heuristics & Filtering
作られたランキングに対して、バランス良く多様なフィードを作成するために、調整を入れていきます。
- ブロックやミュートしたツイートの除外
- 一人の人が連続してFeedに登場しないように、ユーザーの多様性の確保
- In/Out of Networkのバランスを取るように調整
- Feedbackに基づいて、一部のツイートのスコアを下げる
- フォローしている誰かがそのツイートに関与しているか、ツイート主をフォローしているかを保証する(推薦の品質保証の意図)
- スレッドになっているツイートは、もとのツイートからつなげる(文脈の可視化)
- 編集済みのツイートは最新のものに変える
などなど、いろいろやっているらしいです。
Mixing and Serving
ここまでで、おおよそすべての処理が終わっており、最後に広告、フォロー推奨、オンボーディングプロンプトなどの、ツイート以外のコンテンツを混ぜ込んで、Feedとして表示しているらしいです。
Candidate Source
全体像の確認ができたところで、もう一段階深堀りしてみようと思います。 最初はCandidate Sourceについて見ていきたいと思います。
Candidate Sourceでは、膨大な数のTweetの中からユーザーにとって興味のありそうなTLに表示する候補となるTweetを選択します。 ここで選ばれたTweetが後段のHeavy rankerにて優先順位の並べ替えが行われ、(基本的には)優先順位の高いほうから一定数がtimelineとして表示されることになります。

Candidate Sourceでは合計1500件の推薦候補を取得しますが、50%はIn-Network、50%はOut-of-Networkから取得しています。
- In-Network
- ユーザーがフォローしている人の中から関連性の高いTweetを選定
- Out-of-Network
- ユーザーがフォローしている人以外から関連性の高いTweetを選定
- Social Graph
- Tweetやユーザーに対する関係性グラフから関連性の高いツイートを選定
- Embedding Space
- Tweetの埋め込みの距離から関連性を推定し、ツイートを選定
これを処理するコンポーネントとして4種類描かれています。
- search-index
- cr-mixer
- user-tweet-entity-graph (UTEG)
- follow-recommendation-service (FRS)
このうち、cr-mixerは、コードをちゃんと読んでいないのであまり詳しいことはわかってないですが、たくさんのアルゴリズムによるCandidateを統合することでCandidateを作成するコンポーネントになっているようです。 (混ぜ合わせや調整処理を主に行っているようなコンポーネントのようで、あんまりわかってないのでこれについては深入りしません)
search-index
search-indexはその名の通り、検索インデックスを使用して検索された推薦候補になります。 ユーザーがフォローしているユーザーのリストに基づいて、フォロー中のユーザーのTweetを取得することで候補集合を作成します。

この検索はEarlyBirdというTwitter内のTweet検索システムを使ったlight rankerによって優先順位付けされています。 フォロー中のユーザーのTweetに限定されるといってもそれでも数が多いので、ここから更に静的・動的特徴に基づいてスコアリングが行われ、上位のTweetが選ばれるようです。
- 静的特徴
- そのツイートがリツイートかどうか
- ツイートにリンクが含まれているかどうか
- このツイートにトレンドワードがあるかどうか
- ツイートがリプライかどうか
- 文の攻撃性、長さ、読みやすさなど複数の要素に基づいて決められるテキストの静的な品質を表すスコア
- tweepcred
- twitter内におけるpage-rank
- 動的特徴
- いいね、リプライ、リツイート数
- 毒性・ブロックに関するスコア
RealGraph
おすすめを見るユーザーとおすすめに表示されうるTweetしたユーザーとの関係性もスコア影響を与えるようで、これにはRealGraphというアルゴリズムが使用されています。
ユーザーがフォローしているユーザーの中でも、直近のインタラクション数などによって関係性の強さには強弱があると考えられます。 RealGraphではその関係性の強さを推定し、近い将来インタラクションが発生しそうなユーザーに高いスコアを割り当てています。
内部では、直近のユーザーの行動の情報をもとに、近い将来ユーザー間のインタラクション(いいね、replyなど)が発生しそうかをロジスティック回帰によって確率を予測することで、ユーザー間の関係性を推定しています。
user-tweet-entity-graph (UTEG)
UTEGでは、「XXX Liked」のようなユーザーの直接のフォロー範囲外のツイートから推薦候補を取得します。 過去24~48時間のユーザーのエンゲージメントをインメモリで保持しており、それらの中から推薦候補を取得します。
GraphJetにより、重み付きフォローグラフを入力として受け取ってツイートをエンゲージしたユーザーの数・重みに基づいて、ツイートを選定します。(協調フィルタリングに近いアルゴリズム)
GraphJet
GraphJetはTwitterで使用されているuser-tweetの二部グラフをリアルタイムに保持するインメモリグラフ処理エンジンです。 これを使用することで、直近のログデータを使用してユーザーに対してTweetをおすすめしています。
この推薦のベースとなるアルゴリズムはSALSA(Stochastic Approach for Link-Structure Analysis)で、user-tweetの2部グラフ上でのランダムウォークを行うことで、そのTweetに関する訪問回数分布によっておすすめするTweetを推定しています。
ランダムウォークは推薦を行うユーザーからはじまり、このユーザーが関与したTweetをランダムにサンプリングします。そのTweetに対して関与した別のユーザーをランダムサンプリングによって訪問、そこから更にTweetを訪問、といった2部グラフ上のランダムウォークを繰り返すことで、Tweetに対する訪問回数分布が得られます。 これを自分と近い嗜好を持ったユーザーが関与している別のTweetのおすすめ度合いとして使用することで推薦しています。
follow-recommendation-service (FRS)
フォローすべきアカウント・そのアカウントからのツイートを取得します。 Twitterには、Who to followというまだフォローしていないユーザーをおすすめする仕組みがあり、それを用いてユーザー及びそのユーザーによるツイートを取得しています。
内部的にはおすすめユーザーに関するCandidate Generation -> Filtering -> Ranking -> Transform -> Truncationといった一連の処理が行われるようで、先に紹介したGraphJetの他にはSimClustersやTwHINといったアルゴリズムが利用されているようです。
{kind=link}
SimClusters
SimClustersはユーザーの行動をもとに、ユーザーが属するコミュニティを推定し、それをもとに推薦を行うアルゴリズムです。
はじめに、一定以上のフォロワーがいるような影響力のあるユーザーに着目して、これらのユーザーが含まれるコミュニティを発見します。 次に、発見されたコミュニティに対し、その他のユーザーを紐付けていきます。 こうしてユーザーが属するコミュニティを推定していきます。
Tweetについては、各コミュニティによるTweetの人気度を見ることで、Tweetをこれらのコミュニティに関連付けることができます。
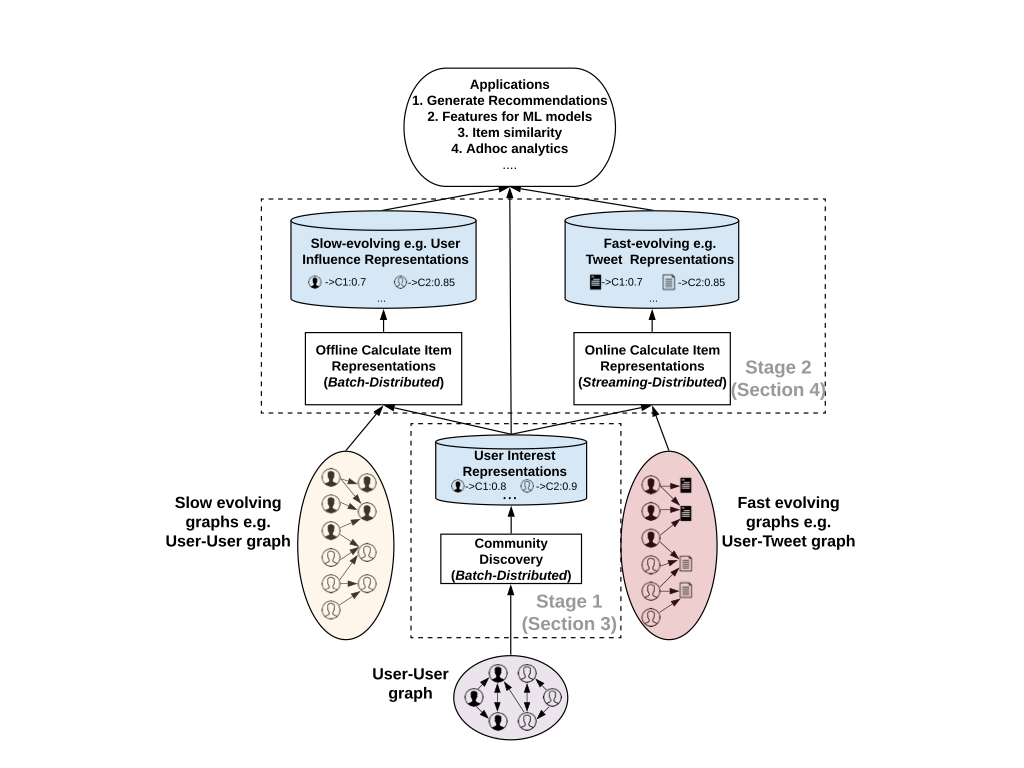
あるコミュニティのユーザーがそのツイートを気に入れば気に入るほど、そのツイートはそのコミュニティと関連付けられるようにEmbeddingを構築していくようです。
TwHIN
TwHINは複数種類のインタラクションをまとめて推薦に活用するアルゴリズムとなっています。

こちらは、Twitterで可能なインタラクション(いいね、RT、follow、など)の単位で、個別にユーザーやTweetのEmbeddingを計算していきます。 個別の種類のEmbeddingが求められたら、インタラクションの種類ごとにk-meansでクラスタリングを行い、クラスタのEmbeddingを計算します。 最後に、ユーザーやTweetについて、それらとインタラクションが発生しているクラスタの寄与度に応じてEmbeddingに荷重を掛けることで、複数のインタラクションを考慮した1つのEmbeddingを計算しているようです。
こうして複数種類のインタラクションに基づいて計算されたembeddingが得られ、これを用いてFRSが行われているようです。
Ranking
推薦候補が得られたら今度はこれらを改めて優先順位付けしていきます。 コンポーネントとしてはheavy-rankerと呼ばれているらしく、こちらに概要が記載されています。
Rankingに使用している特徴量としてはAggregate/NonAggregate/Embedding Featuresの3つに大別されており、そのなかで更に細かく特徴量定義されて使用されています。 ここは細かいので、詳細は下記をご参照ください。
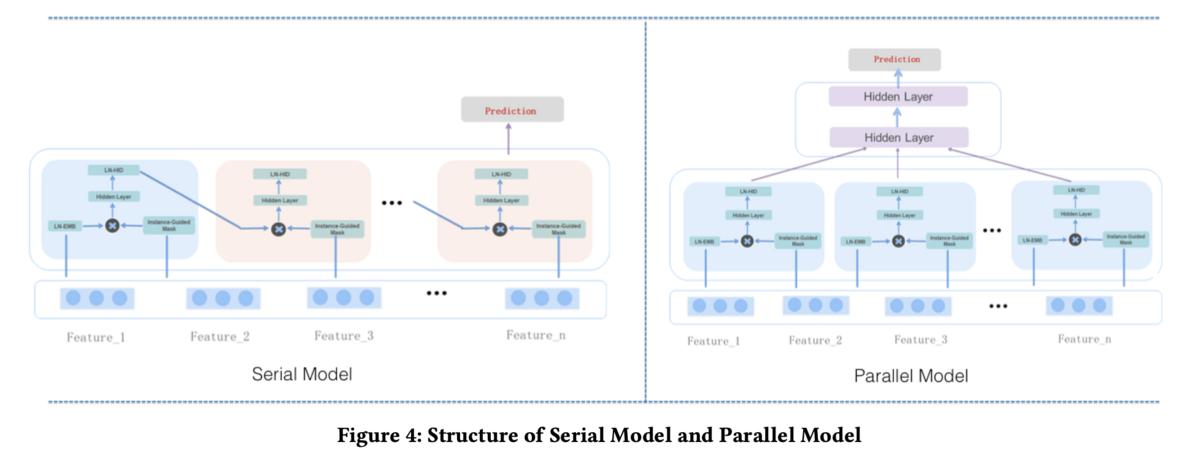
MaskNet
ランキングに使用しているアルゴリズムとしては、MaskNetと呼ばれるCTR予測モデルを使用しているようです。
MaskNetの特徴的な点は、instance-guided maskと呼ばれる特徴量ごとの重要度を抽出する層が使用されている点です。(attentionのような役割)

このinstance-guided maskにより、重要視する特徴量を自動で調整し、特徴量の相互作用を効率よく学習しているようです。 実際にはこれをすべての特徴量で並列におこない、その後それを集約することで予測をしているようです。
参考文献
この記事を書くにあたって、下記の文献を参考にさせていただきました。
- GitHub - twitter/the-algorithm: Source code for Twitter's Recommendation Algorithm
- Twitter's Recommendation Algorithm
- Twitterのレコメンドの仕組みを解説する - Qiita
- Twitter Recommendation Algorithmについて
- Twitter「おすすめ」に載る方法 アルゴリズムから暴かれた“優遇されるツイート” - KAI-YOU.net
- Twitter の検索システム、Earilybirdの論文を読む | hurutoriya
論文メモ
ブログに書いてあった論文についてはこの辺にメモがあります。
その他、関連する論文のメモはこちら。
- EarlyBird
- userのTweetを高速に検索する検索サービス
感想
以上、時間かけてチマチマ読んでみた内容のメモでした。まだ目を通していない論文がチラホラあるのと、間違ってる可能性もありますので、 興味がある方はぜひ実際にGitHubのリポジトリを読んで中身を紐解いてみてください。
個人的には、コードリーディングもしてもうちょっと詳細を見ていきたいところですが、半分以上Scalaで書かれていて重い腰が上がらないのが正直なところです。 このへんはきっと神様みたいな人が解説記事書いてくれると信じてます🙏(他力本願)