
最近RAGアプリケーションの評価やその管理ツールについて調べることがありました。 今回はRAGアプリケーションでの実験管理に使用できるPhoenixを使ってみたのでそのメモです。
RAGアプリケーションと評価
Retrieval-Augmented Generation (RAG)は、LLMに外部の知識ソースからの追加情報を提供することで、LLM自体が知らない知識を補い、より正確で文脈に沿った答えを生成するアプリケーションです。 大まかには下記のような流れで動作します。
- ユーザーからのクエリをもとに関連するドキュメントを検索 (retrieve)
- ユーザーのクエリ、関連するドキュメントを含めた形でプロンプトを動的に作成 (Augment)
- LLMによって回答を生成 (Generate)
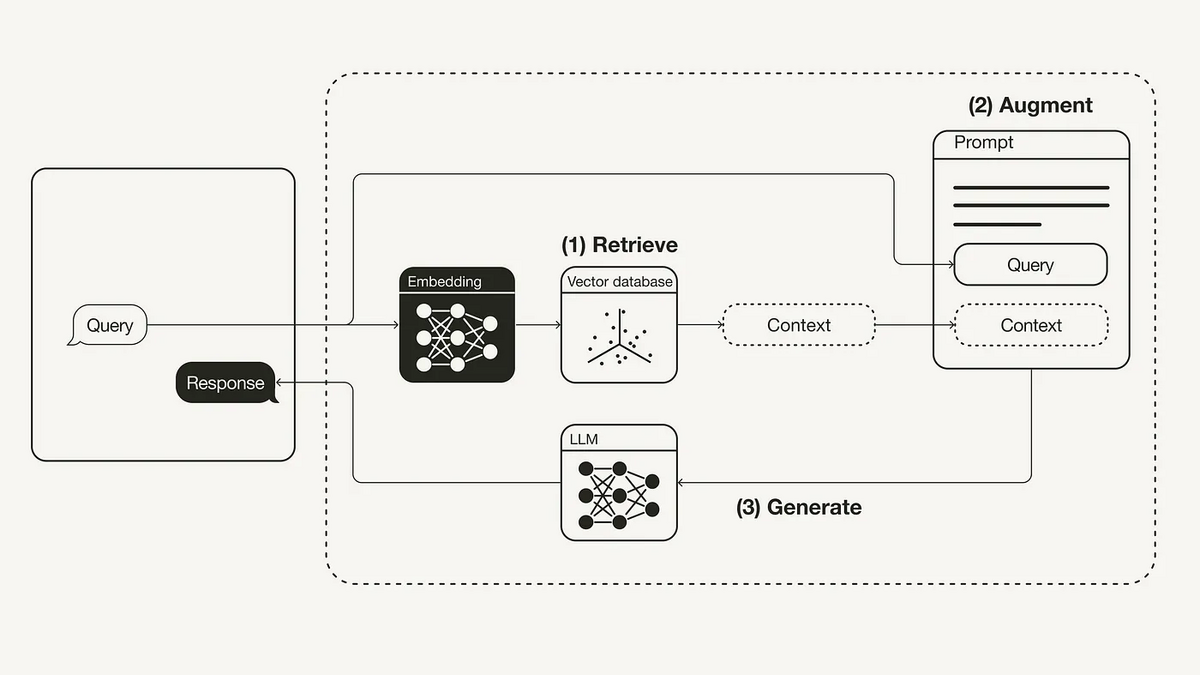
このように組み上げられるRAGアプリケーションですが、このアプリケーションの評価やその精度のトラッキングについては一つ厄介なポイントになっています。
RAGアプリケーションの評価
先に示したように、RAGでは質問をもとにRetrievalとGenerationを通じて最終的な回答を生成しています。 そのため、RAGアプリケーションの品質はこれら2つの段階が組み合わされた結果となります。
RAGアプリケーションの改善をすることを考えると、RAGのどのコンポーネントの精度がボトルネックになっているのかを適切に見極める必要があります。 そのためには、仮に質問に対して誤った回答を返した場合にはRetrievalが原因なのかGenerationが原因なのかを識別できるように管理されていることが求められます。
現在RAGアプリケーションを評価するライブラリとしてはRAGASが広く知られています。
RAGASではRetrievalとGenerationそれぞれで評価指標を定めています。
- Generation
- faithfulness: 与えられたコンテキストに対する回答と事実の一貫性
- answer relevancy: 生成された回答が与えられたプロンプトに対してどれだけ適切であるか
- Retrieval
- context precision
- context recall

もちろんRAGASで考えられている評価指標以外にも考えることはあるかと思いますが、RAGアプリケーションを継続的に改善していくにはRetrievalとGenerationを切り分けて評価を確認することが良さそうに思えます。
Arize Phoenix
Phoenixは、実験、評価、トラブルシューティングのために設計されたオープンソースライブラリです。
Phoenix is an open-source observability library designed for experimentation, evaluation, and troubleshooting. It allows AI Engineers and Data Scientists to quickly visualize their data, evaluate performance, track down issues, and export data to improve. Arize Phoenix | Phoenix
本家のページは下記になります。
今回対象にしているRAGに関しては、下記のデモサイトを実際に触ってもらうのが感じを掴むにははやいと思います。
類似ツール
この手のLLMOps系のツールでArize Phoenixと似たようなことができるツールとしては下記のようなツールが挙げられます。
- SaaS
- LangSmith
- HoneyHive
- PromptLayer
- OSS
- Langfuse
- TruLens
Arize Phoenixの他のツールとざっと比較した所感としては、下記あたりが強みかなと思います。
- OSSでローカルで使える
- 検索関係のモニタリング・可視化機能が他のツールより充実(している気がする)
現状だとLangSmithが一番メジャーな気はしますし最近だとLangfuseが話題になっていました。 この手のツールのうちどれを使うか選定する際の筆頭のツールではないかもしれませんが、ローカルでの開発がメインだったり、検索関係のモニタリング等に課題感がある場合には候補になってくるかもしれませんね。
使ってみる
Tutorial
はじめに公式で提供されているチュートリアルを通じて感じを掴んでみようと思います。
チュートリアル通りにWhat did the author do growing up?と質問したところThe author focused on writing short stories and programming, particularly experimenting with early programming languages like Fortran on an IBM 1401 computer during their time in 9th grade.という回答が得られました。
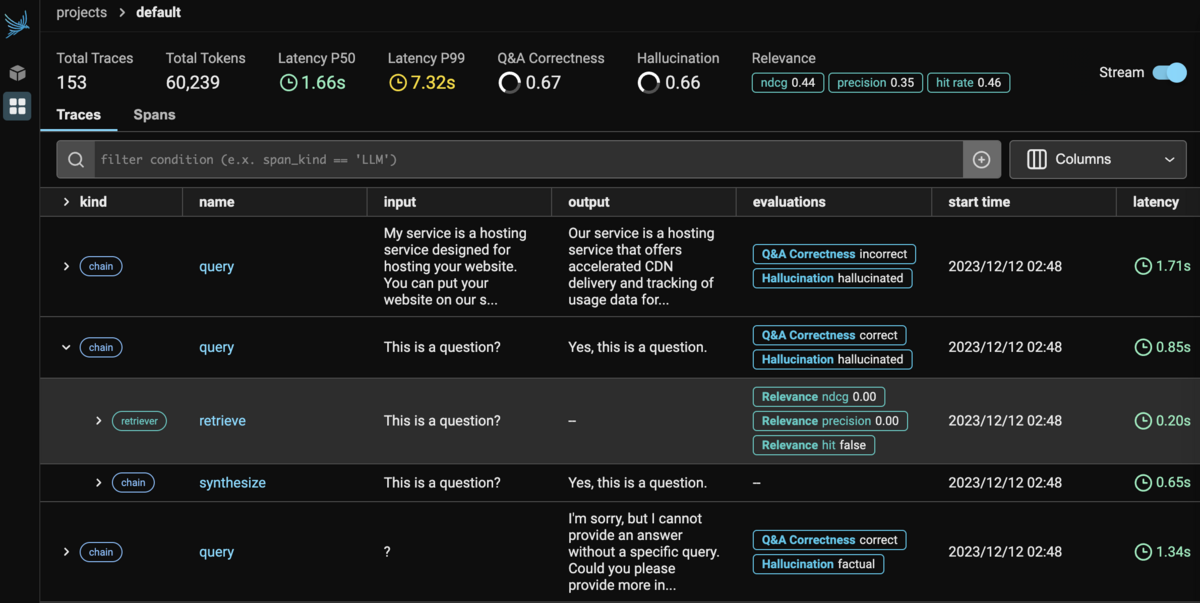
このときのPhoenixの画面は下記のようになります。

RetrieveからGenerationまでどのような動作をしたかは下記のようにフローで確認することができます。

このあたりの見た目はLangSmithなどと同様の使用感で使うことができますね。
トラッキング自体は下記のコードを実行するとローカルにトラッキング用のサーバーが起動するので、それ以後はOpenAIとの通信やLangChain、LlamaIndexで通信するとそれを自動でキャプチャして行くようです。
import phoenix as px session = px.launch_app()
追加で計算したndcgやprecisionなどは後からサーバーへ通信してダッシュボードに反映する形のようです。
from phoenix.trace import DocumentEvaluations, SpanEvaluations px.Client().log_evaluations( SpanEvaluations(dataframe=ndcg_at_2, eval_name="ndcg@2"), SpanEvaluations(dataframe=precision_at_2, eval_name="precision@2"), DocumentEvaluations(dataframe=retrieved_documents_relevance_df, eval_name="relevance"), )
こんな感じに反映されます。

要するに
- 基本的に
launch_appしておけばイベントをトラッキングしてくれる - ndcgやprecisionなど、後から計算した指標は
log_evaluationsで追記する
感じで使っていくみたいです。
ローカルでの管理
チュートリアルではColabを使ってみたので、今度はトラッキングした結果を永続化できるようにしたくなるかもしれません。 ローカル環境でPhoenixのサーバーを構築するのはこちらを使えばできそうです。
※M3 MacだとなんだかPhoenixが動かなかったので今度Intel 環境で改めて試してみようと思います
参考文献
感想
Colab環境で動かすだけなら結構簡単に使えそうなことがわかりました。 使ってみただけですが、今度もうちょっと別の形でいじってみようと思います。