2023年くらいからLLMがブームになってますが、自分はというとChatGPTをそのまま使っていたくらいで、それ以上はLLMに特に触っていませんでした。 正直そんなに興味はなかったんですが、まったく知らないのはそれはそれでまずいと思うようになりました。
ということで、今回はLLMを使用する代表的な設計パターンであるRAGについてサラッと触っていきたいと思います。
RAG?
多分これを読んでいる人には釈迦に説法な気はしますが、RAGについて一応書いときます。
RAGは、大規模言語モデル(LLM)と外部知識検索を組み合わせた 生成AI設計パターン です。 RAGは、リアルタイムデータを生成AIアプリケーションに接続するために必要です。 そうすることで、推論時にデータをコンテキストとしてLLMに提供することで、アプリケーションの精度と品質が向上します。 Databricks での Retrieval Augmented Generation (RAG) | Databricks on AWS
LLMは基本的に学習に使用されたデータにある知識しか保持しておらず、学習時のデータに含まれていなかった知識に関して回答することができないという問題があります。この問題に対して解決するアプローチの一つがRAGです。
RAGの大まかな処理は下記のようになっています。
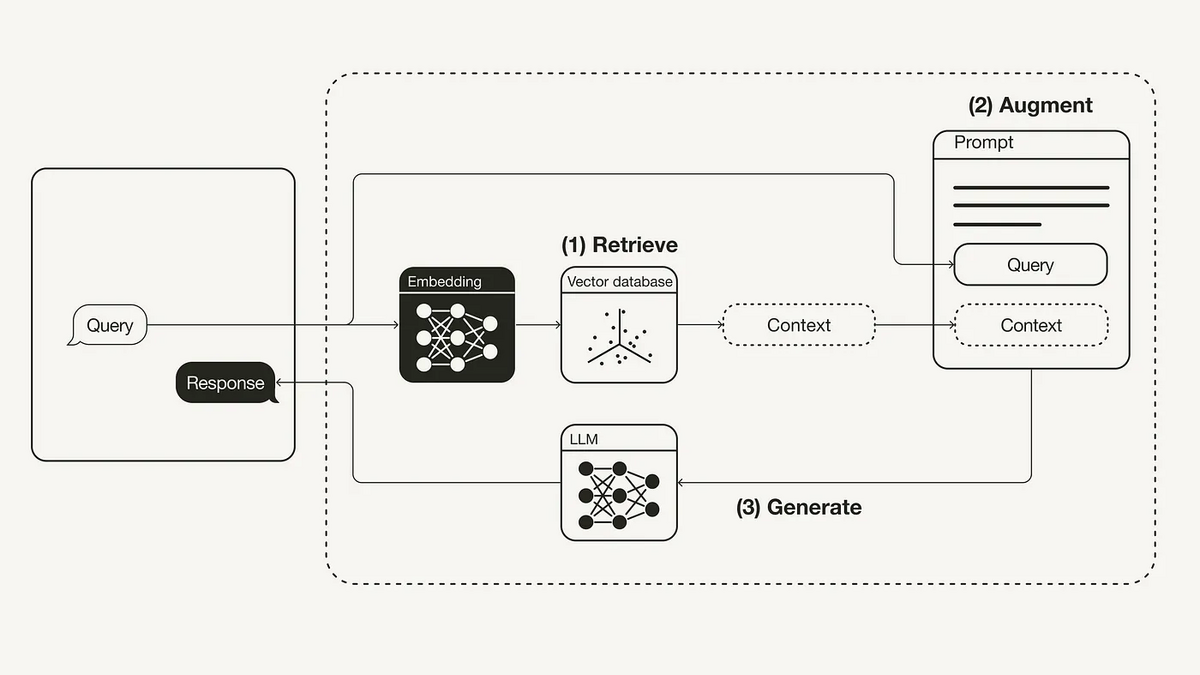
RAGを使った応答時の大まかな処理の流れは下記の3ステップになっています。
- ユーザーのクエリに対して関連するドキュメントを検索
- ユーザーのクエリと検索されたドキュメントをあわせてプロンプトを作成
- プロンプトを用いて回答を生成
この処理によって、LLMが学習時に獲得しない知識でもドキュメントとして与えることあたかもすでに知っていたかのようにLLMに回答させることができます。
LlamaIndex
RAGアプリケーションを実装するのによく使われるのはLangChainだと思いますし、実際LangChainを使用したRAGの構築を解説した書籍も出版されています。*1
単にRAGアプリケーションを構築するだけなら、LlamaIndexというライブラリも使用することもできます。
LlamaIndexを簡単に説明するとこんな感じになります。
結論から言うと,Lllamaindexは独自のデータを使ったQAチャットができるLLMを簡単に作成できるライブラリです.Lllamaindexも内部的にはLangchainを使っているみたいです. LlamaindexとLangchainの違いとは? #NLP - Qiita
RAGを実装するという範囲であれば正直どっちを使っても実装できますが、今回はLlamaIndexを使って実装をしていきたいと思います。(ちょっと使ってみたかったので)
良いところ
LlamaIndexはRAGを作るための便利な機能が揃っているので、簡単にRAGを作ることができます。 ドキュメントを見る感じ、大まかな機能群としてはこんな感じです。
- Data connectors: ファイルアクセスのためのツール
- Data indexes: LLMが利用しやすい中間表現
- Engines: クエリ受信時やチャット生成時のためのツール
- Data agents: LLMによって拡張されたのナレッジワーカー
- Application integrations: 他のエコシステム(LangChain, Flask, etc...)を使用するためのツール
詳しいことはあんまりわかりませんが、便利ツールが揃っているのがいいところです。
とりあえず作ってみる
文字で説明を書くより実際に作ってみたほうが簡単さが伝わる気がするので、実際に使ってみたいと思います。
データセット作成
何を作るにしてもデータセットが必要になります。 オープンソースのテキストを使えればよかったんですがライセンスとか色々めんどくさそうなんで、今回は自分のブログ記事を使おうと思います。(なので、もし試してみたいという方はお手元のデータでどうぞ)
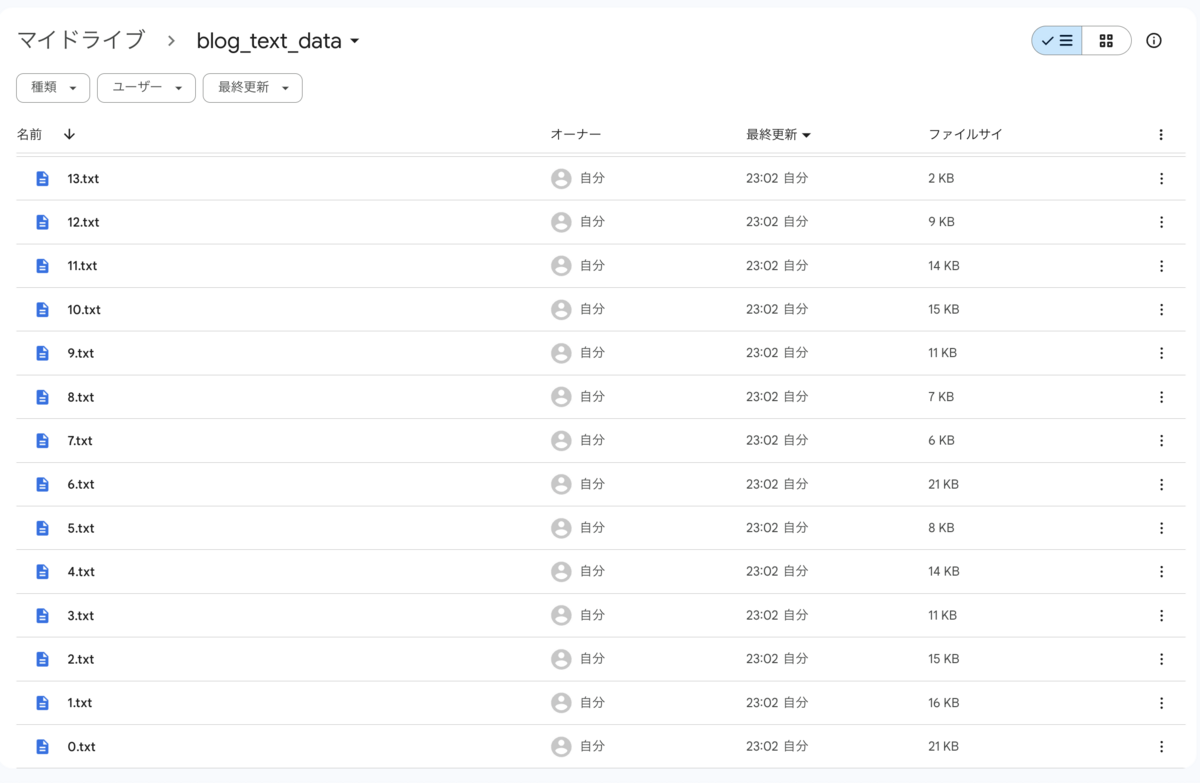
テキストの品質は残念な感じですが、サンプルプログラムならこんなので十分でしょう。
LlamaIndexを使った実装
サンプル実装が公開されていたりするので、まずはこちらを使っていきたいと思います。
サンプルアプリケーションを作りたいだけなら、ほぼこれで事足りそうです。
Dockerで動かしたかったりするので下記を参考にちょっと修正を加えていきます。
動かしてみる
自分はDockerの中で動かしたかったので、Dockerを使っています。
Docker imageを下記のコマンドでビルドします。
docker compose build
実際の起動は下記のコマンドで動きます。
docker compose up
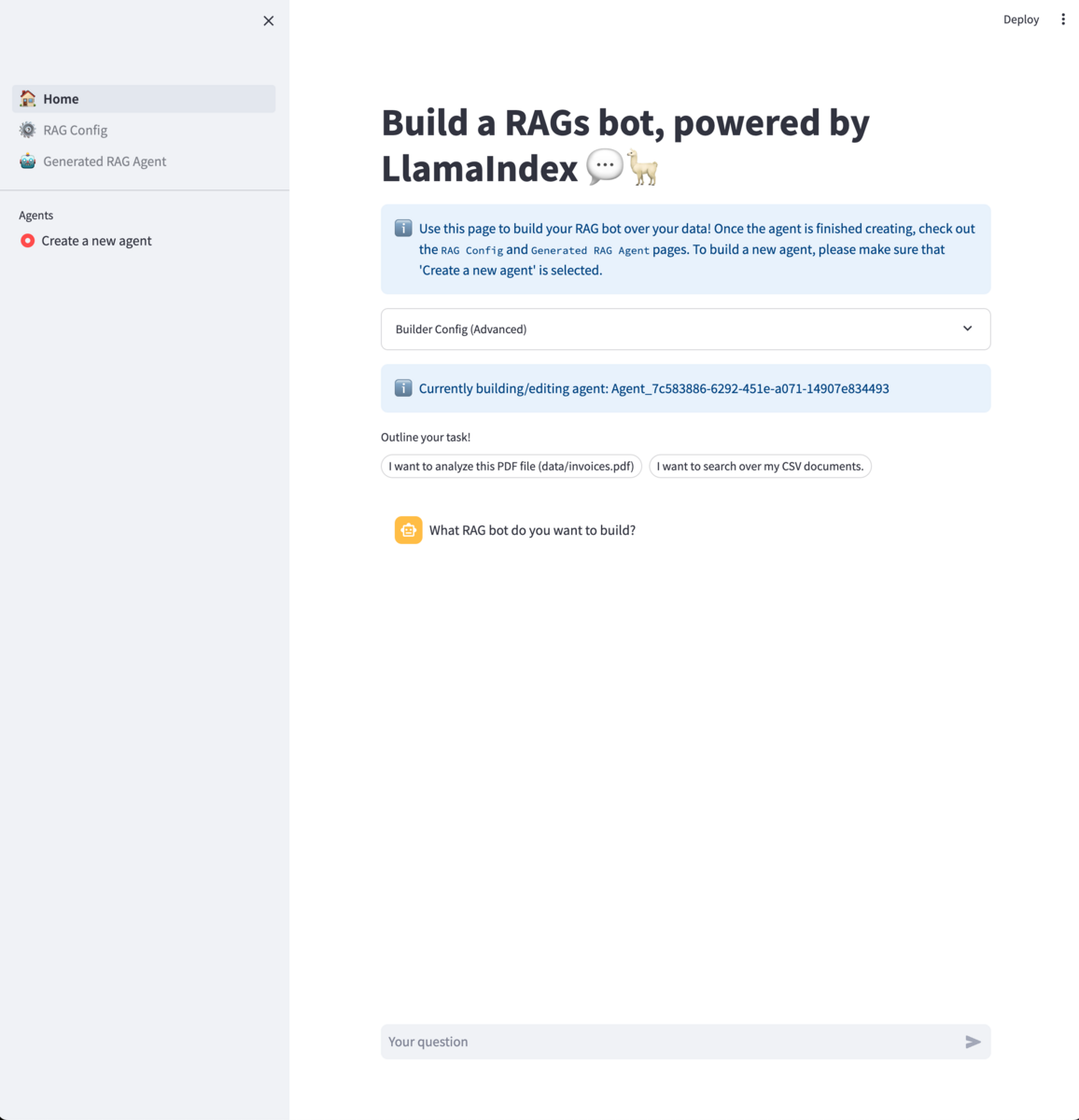
とりあえずサーバーが起動したら、http://localhost:8501/にアクセスするとこんな感じの画面が出てきます。
下準備
RAGを動かすにあたっていくつか下準備が必要になるので、やっていきます。
.streamlit/secrets.tomlにopenai_keyを記述openai_key = "sk-XXXXXXというのを1行書いたファイルを用意する
data/にRAGで呼び出したい元データのファイルを配置- RAGをやるエージェントをchatで作成
- Homeタブでchatで作ってました
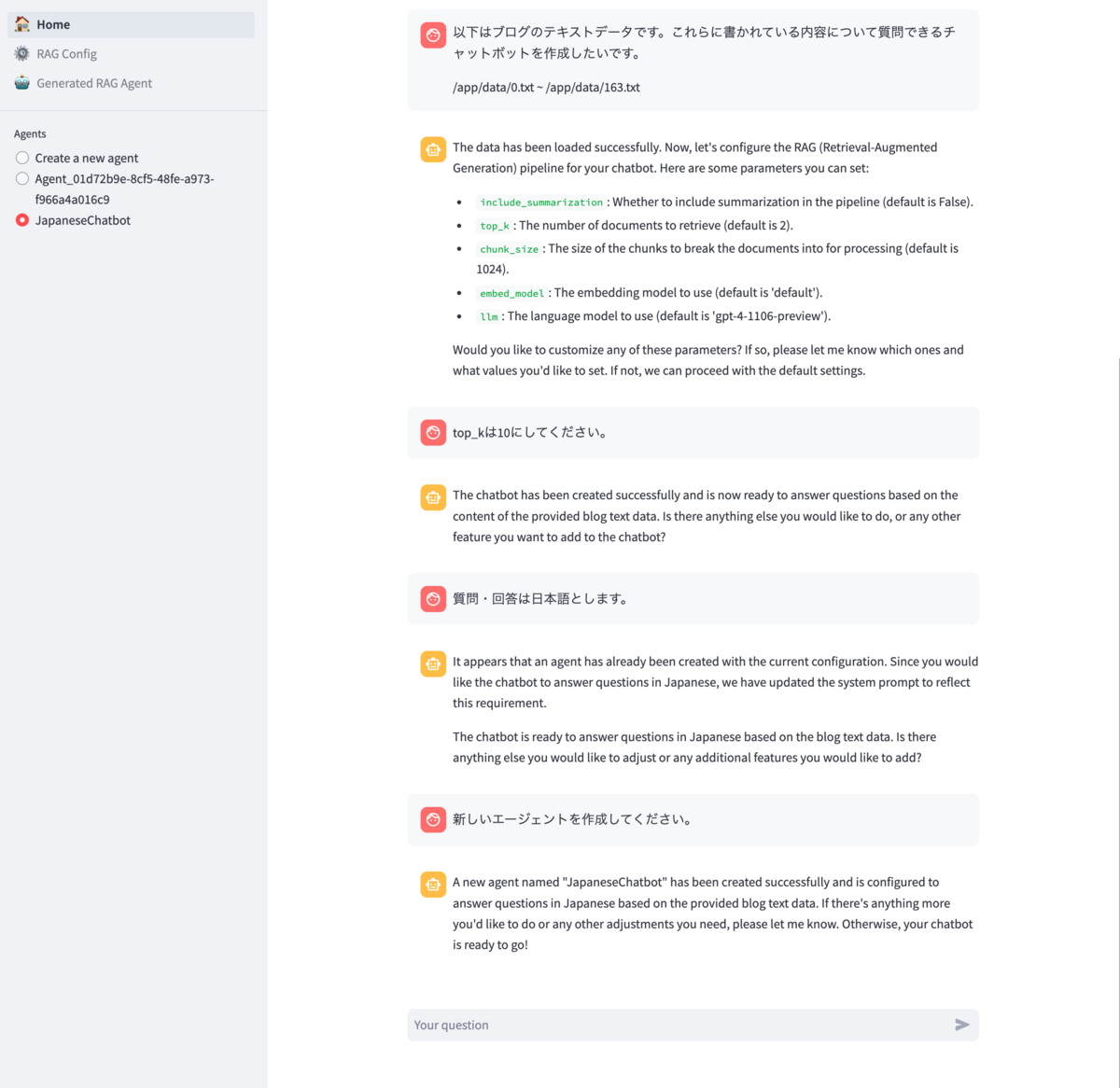
- configでちょっといじる
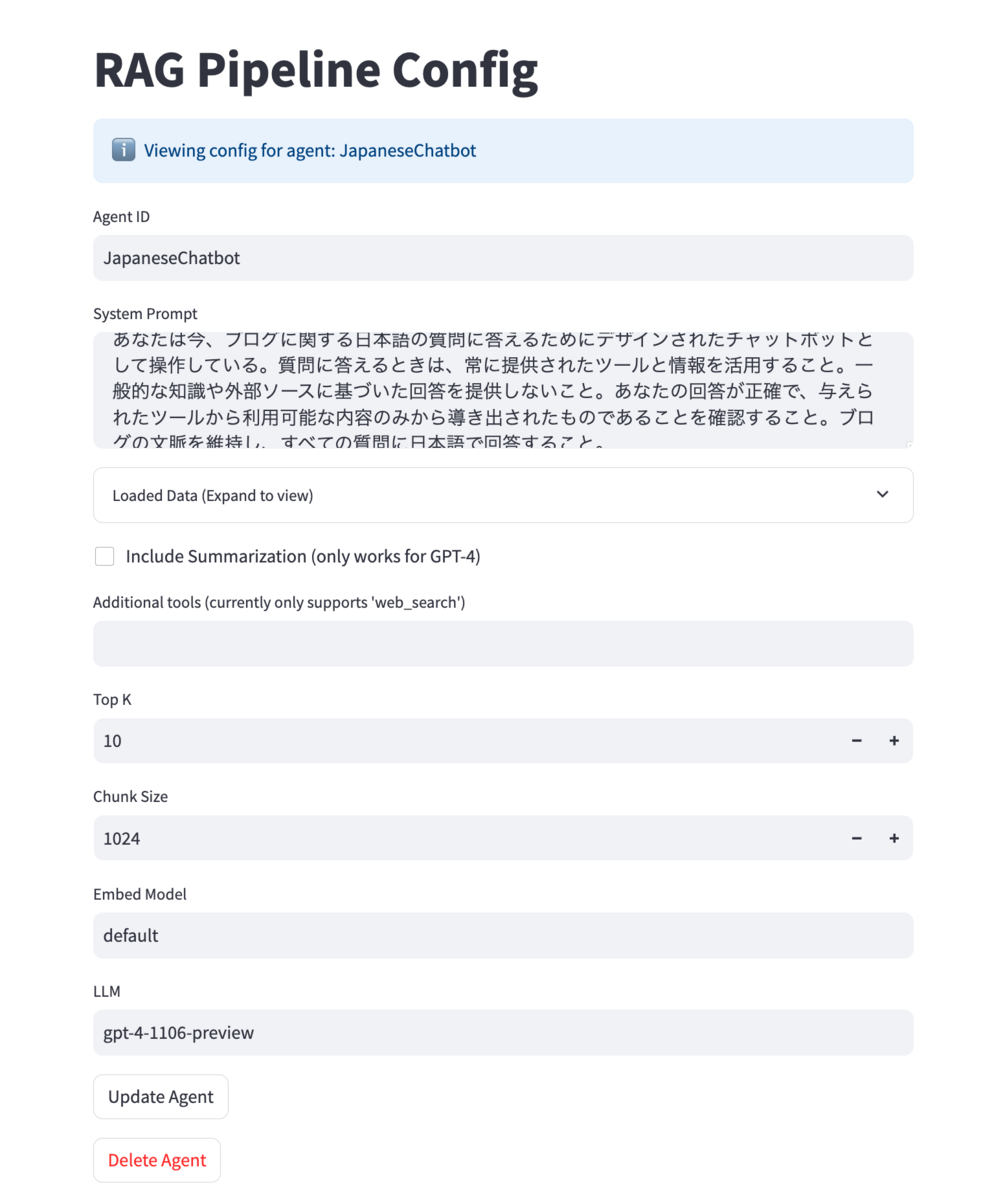
動作確認
こんな感じのRAGアプリケーションができました。
動かしただけ。 pic.twitter.com/7R1TTcV7Zn
— 野川の側 (@nogawanogawa) 2024年2月25日
ただ自分の持ってるテキストファイル突っ込んだだけですが、お手軽RAGアプリがちゃんと動きました。
主要なコードを読む
とりあえず動きはしたので、後はちょこっとコードを読んでいこうと思います。
コードの中身はこんな感じになってます。
rags % tree
.
├── 1_�\237\217�_Home.py
├── Dockerfile
├── LICENSE
├── Makefile
├── README.md
├── core
│ ├── __init__.py
│ ├── agent_builder
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── loader.py
│ │ ├── multimodal.py
│ │ └── registry.py
│ ├── builder_config.py
│ ├── callback_manager.py
│ ├── constants.py
│ ├── param_cache.py
│ └── utils.py
├── data
│ ├── 0.txt
│ ├── 1.txt
│ ├── ...(他たくさん)
│ └── 99.txt
├── docker-compose.yml
├── pages
│ ├── 2_�\232\231�\217_RAG_Config.py
│ └── 3_�\237�\226_Generated_RAG_Agent.py
├── pg_essay.txt
├── pyproject.toml
├── requirements.txt
├── st_utils.py
└── tests
└── __init__.py
この内、pages/以下と1_🏠_Home.pyはstreamlitのコードで。画面の表示と入力の受取のコードです。
core/がアプリの実際の挙動が書かれた部分になっています。
RAGをやっているときの主な動作を見ていくと、なんとなくこの辺でRAGの処理が始まっているみたいです。
with st.chat_message("assistant"): with st.spinner("Thinking..."): response = agent.chat(str(prompt)) st.write(str(response)) # display sources # Multi-modal: check if image nodes are present display_sources(response) add_to_message_history( "assistant", str(response), extra={"response": response} )
その中で、chatが呼び出されてここで検索・OpenAIへの問い合わせが行われてるみたいですね。
def chat( self, message: str, chat_history: Optional[List[ChatMessage]] = None ) -> AGENT_CHAT_RESPONSE_TYPE: """Main chat interface.""" # just return the top-k results response = self._mm_query_engine.query(message) return AgentChatResponse( response=str(response), source_nodes=response.source_nodes )
rags/core/utils.py at ba302bf161d0d8ab1fc79e32abccffe4e4ad4a4a · nogawanogawa/rags · GitHub
読んでみると、self._mm_query_engine.query(message)ってところで、検索と応答をどっちも取得しているみたいですね。
この辺見ても、応答のテキストとnodeを一緒にresponseとして受け取っているみたいなので、chatを呼び出すだけで検索結果と応答を両方作ってくれているみたいですね。
なにか機能を足そうと思ったらこの辺りからいじれば良さそうですね。
リポジトリ
ほぼほぼベースにしたリポジトリと同じですが、一応コードは公開しておきます。 (Dockerfile + docker-composeだけ追加してる感じ)
参考文献
この記事を書くにあたって下記の文献を参考にさせていただきました。
- Retrieval-Augmented Generation (RAG) とは? | NVIDIA
- LlamaIndex, Data Framework for LLM Applications
- Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation | by Leonie Monigatti | Towards Data Science
- GitHub - run-llama/rags: Build ChatGPT over your data, all with natural language
- LlamaIndexのRAGsを試す
感想
以上、やってみた記事でした。 この続きでいくつかやりたいことがあるので、それは気が向いたら続きを書こうと思います。