
この記事はMLOps Advent Calendar 2023の23日目の記事です。
以前、Feature Storeに関する記事を書いていました。
この記事を書いた当時は「Feature Storeってこんな感じかー」って思って終わってしまい、どんな感じに使うのかは触っていないので感覚があまりわかっていませんでした。
今回は、Feature StoreのメジャーなライブラリにFeastを使ってみます。 そもそもFeastに関する日本語の文献がそこまで多くは見当たらなかったので、自分の備忘録として使い方を残しておこうと思います。
Feature Store?
Feature Storeを一言で説明すると、「機械学習の学習・推論に使用することを目的として、特徴量を作成・更新・保存・探索・アクセスするための管理システム」と個人的には理解しています。*1
Feature Storeのモチベーションや概要などはは過去に記事を書いていたりするのでそちらをご参照ください。
Feature Storeを使っているという話も最近ではちらほら聞こえてくるので、だんだん注目されてきている技術だと個人的には感じています。 また、現在は主要なクラウドベンダーからもFeature Storeのサービスが出ていたりして「使ったことは無いけどFeature Storeという存在はなんとなく知ってる」という人も多いかもしれません。
Feastとは
今回注目しているFeastはFeature Store のOSSの一つです。
完全に個人的印象ではありますが、Feature StoreのメジャーなOSSはFeastもしくはHopsworksあたりかな、という印象を持っています。
その他のライブラリに関してはこちらをご参照いただければと思います。
機能
動作確認をするにあたってざっくり構成を把握していたほうが良いと思うので、先にFeastの概念的構成について確認します。 Feastの構造についてはGitHubの図が参考になります。
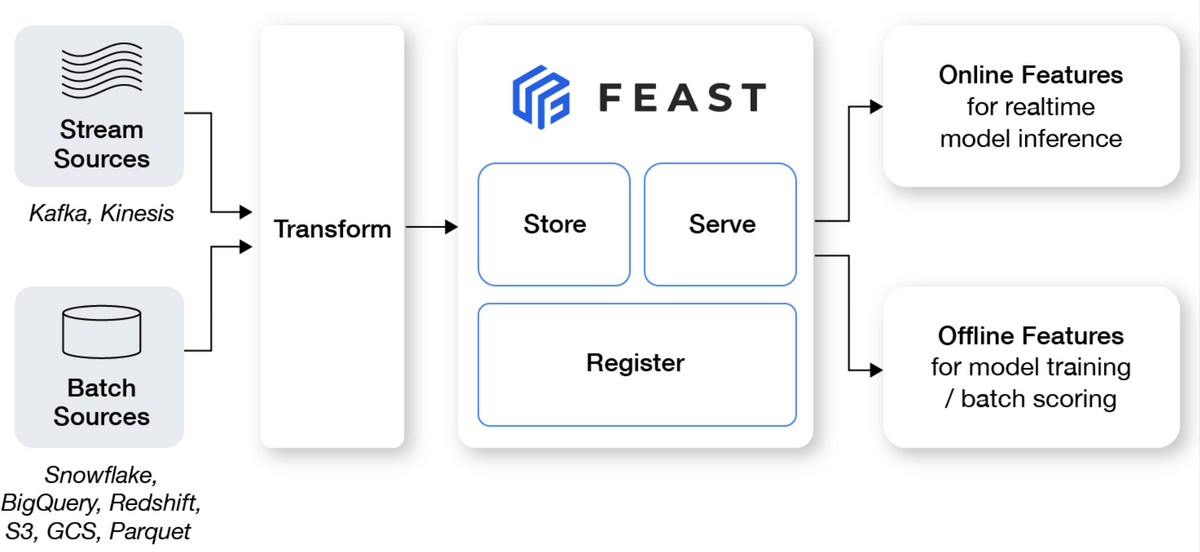
Feastは主に下記の4つの機能を組み合わせて動作しています。
| 機能 | |
|---|---|
| Transform | 生データから特徴量として使用できる形に変換 |
| Store | 変換した特徴量を保存 |
| Register | 保存した特徴量を呼び出し可能にするために登録 |
| Serve | 呼び出しのクエリに基づいて該当する特徴量を応答 |
生データを事前に変換(Transform)した特徴量を保存(Store)・呼び出して使用できるように登録(Register)し、呼び出しのクエリに応じて対応する特徴量を提供(Serve)するというのが主な動作の流れです。
概念構造
Feastのワークフローについて、概念構造についても確認します。 Feastの処理は下記のような概念図で表現されています。
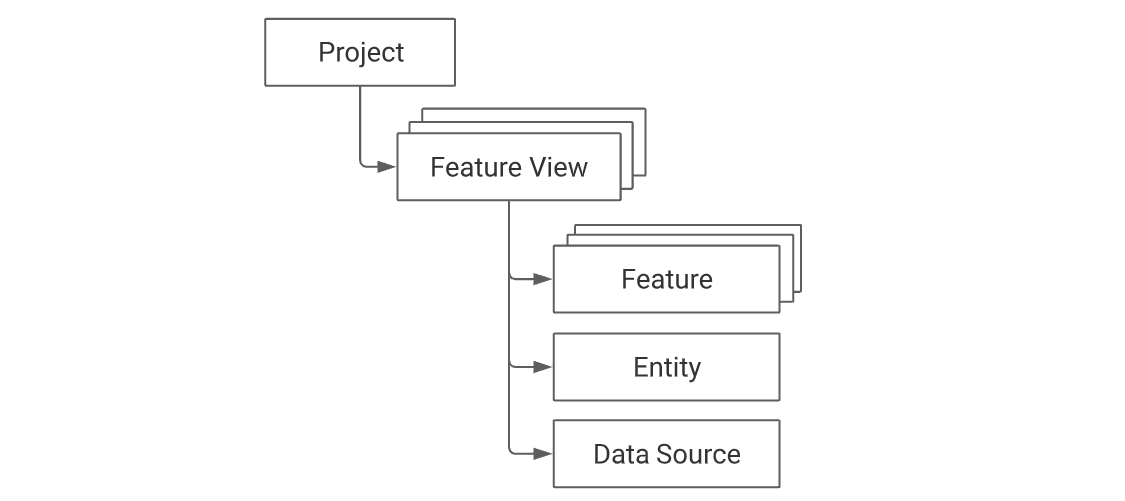
ここには下記のような説明が記載されています。
The top-level namespace within Feast is a project. Users define one or more feature views within a project. Each feature view contains one or more features. These features typically relate to one or more entities. A feature view must always have a data source, which in turn is used during the generation of training datasets and when materializing feature values into the online store. Overview - Feastより引用
DeepL先生に翻訳してもらうとこんな感じです。
Feastのトップレベルの名前空間はプロジェクトです。ユーザーは、プロジェクト内で1つまたは複数のフィーチャー・ビューを定義します。各フィーチャービューには、1つまたは複数のフィーチャーが含まれます。これらのフィーチャーは、通常、1つまたは複数のエンティティに関連しています。フィーチャービューには必ずデータソースが必要で、トレーニングデータセットの生成時や、フィーチャーの値をオンラインストアにマテリアライズする際に使用されます。
EntityやFeatureの考え方は次のような図でも表現されています。

RDBでいうところの、Entityはキー、Featureは紐づいているその他のカラムのようなイメージのようです。
まとめると、超ざっくりとした説明はこんな感じです。
| 名称 | 説明 |
|---|---|
| Project | Feastのトップレベルの名前空間 |
| Feature View | Projectに紐づくView |
| Feature | Feature Viewの1つのカラム |
| Entity | Feature Viewのキー |
| Data Source | データの取得元 |
このような名称・構造を想定して処理を記述していきます。
使ってみる
概念構造がある程度わかったところで、どんなもんなのか使ってみたいと思います。
環境準備
ローカルのDocker環境で遊べるように環境を準備します。
最初はこれのExample 0 でやります。 コンテナの中に入るのはこんなコマンドで行けるはずです。
$ docker compose run -p 8888:8888 feast bash
※8888番portを開けているのはブラウザからGUIにアクセスできるようにするためです。あとで紹介しますがfeastにはGUIで内容を確認する機能も提供されており、ブラウザ経由でアクセスして使用できるようになっています。
Example 1 : Quick Start
最初はQuick Startをなぞりつつ感じを掴んでみたいと思います。
コンテナの中で下記のコマンドでFeast Projectを作成します。
$ feast init my_project
すると、下記のようなファイルが自動で作られます。
my_project
├── README.md
├── __init__.py
└── feature_repo
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-310.pyc
│ ├── example_repo.cpython-310.pyc
│ └── test_workflow.cpython-310.pyc
├── data
│ └── driver_stats.parquet
├── example_repo.py
├── feature_store.yaml
└── test_workflow.py
主なファイルをざっくりと紹介すると、ドキュメントを見る限り、
- data/ : storeするファイルの置き場, 現状だとdemo用のparquetが入ってる
- example_repo.py : 特徴量のdemo用の定義
- feature_store.yaml : データソースがどこであるかなどの定義
- test_workflow.py : Feastの主要コマンドの実行方法のサンプルファイル
のようですね。
主な作業ディレクトリはmy_project/feature_repo配下なので、移動しておきます。
$ cd /usr/src/app/my_project/feature_repo
apply
最初にfeast apply のコマンドを実行します。
$ feast apply
この処理は、カレントディレクトリ内のPythonファイルの中からview/entityの定義を読み取ります。 定義に従って、スキーマを登録・データソースをからデータを取り込んでいきます。 言ってしまえばこのコマンド一つでFeature Storeの準備完了です。
今回はexample_repo.pyに定義が書いてあるので、それを読み込む形になっています。
登録した特徴量をGUIで確認してみる
実際にどんな特徴量が登録されたのか確認してみます。 特徴量の登録状況を確認するときは、feature storeの状態を確認するためのサーバーを立ち上げます。
$ feast ui
https://localhost:8888 へアクセスすると、ブラウザでこんな画面を確認できるかと思います。
作成された特徴量について確認してみると、こんな感じです。
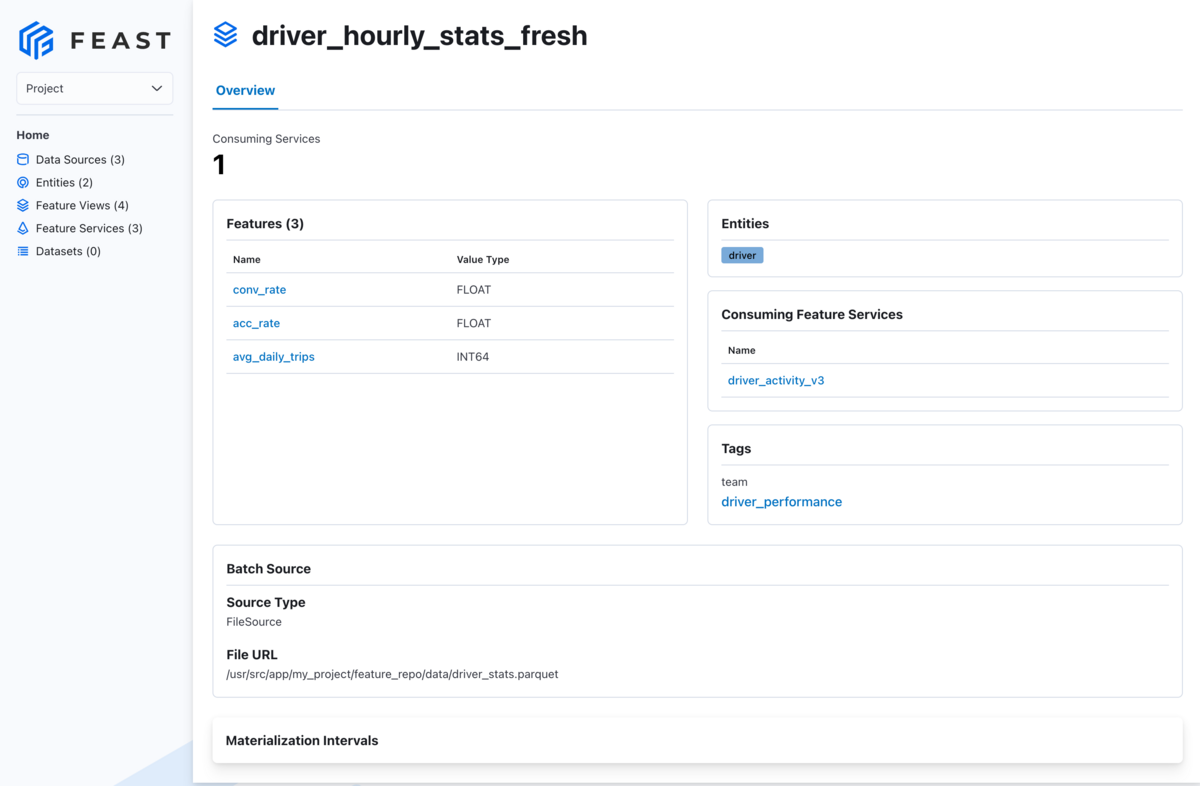
例えばdriver_hourly_stats_fresh というviewでは、
- Entity:
driver - 紐づくFeature:
conv_rate,acc_rate,avg_daily_trips
が設定されていることがわかります。
workflowを一巡り
スキーマの設定ができていることが確認できたところで、今度は実際にデータを呼び出してみます。 これに関しては、実行はtest_workflow.pyを実行するだけです。
$ python test_workflow.py
サンプルのtest_workflow.pyではdemo用のサンプルデータセットを使っています。
ここでは、
- 特徴量の定義の登録(
feast applyコマンド) - 学習用データセットの生成
- バッチスコアリング用データの生成
- オンラインストアに特徴量を取り込み (fetch_online_features)
- オンラインストアから特徴量を取得
- ストリーミングの特徴量をオフライン・オンラインのストアに取り込み
の流れで記述されています。
test_workflow.py 一部抜粋
def run_demo(): store = FeatureStore(repo_path=".") print("\n--- Run feast apply ---") subprocess.run(["feast", "apply"]) print("\n--- Historical features for training ---") fetch_historical_features_entity_df(store, for_batch_scoring=False) print("\n--- Historical features for batch scoring ---") fetch_historical_features_entity_df(store, for_batch_scoring=True) print("\n--- Load features into online store ---") store.materialize_incremental(end_date=datetime.now()) print("\n--- Online features ---") fetch_online_features(store) print("\n--- Online features retrieved (instead) through a feature service---") fetch_online_features(store, source="feature_service") print( "\n--- Online features retrieved (using feature service v3, which uses a feature view with a push source---" ) fetch_online_features(store, source="push") print("\n--- Simulate a stream event ingestion of the hourly stats df ---") event_df = pd.DataFrame.from_dict( { "driver_id": [1001], "event_timestamp": [ datetime.now(), ], "created": [ datetime.now(), ], "conv_rate": [1.0], "acc_rate": [1.0], "avg_daily_trips": [1000], } ) print(event_df) store.push("driver_stats_push_source", event_df, to=PushMode.ONLINE_AND_OFFLINE) print("\n--- Online features again with updated values from a stream push---") fetch_online_features(store, source="push") # print("\n--- Run feast teardown ---") # subprocess.run(["feast", "teardown"])
※ デフォルトでfeast teardownのコマンドが含まれていますが、これをすると初期化されてしまうので、ここではコメントアウトして使っています。
以下では、ここで使用されているfeastの主な処理を確認していきます。
get_historical_features
オフライン(リアルタイム性が必要ない状況)での特徴量検索はget_historical_featuresメソッドを使って利用することができます。
EntityとFeature Serviceを渡すと該当する特徴量を取得できる様になっています。
training_df = store.get_historical_features(
entity_df=entity_df,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
"transformed_conv_rate:conv_rate_plus_val1",
"transformed_conv_rate:conv_rate_plus_val2",
],
).to_df()
materialize_incremental
Feature Storeをオンライン(リアルタイムにデータが更新される状況)で使用するには、Materialize/Materialize incrementalコマンドによって、Feature Viewからオンラインストアにデータをロードする処理になっています。
store.materialize_incremental(end_date=datetime.now())
push
オンライン/オフラインストアに対して、特徴量を追加する際にはPush処理が使用されます。
event_df = pd.DataFrame.from_dict(
{
"driver_id": [1001],
"event_timestamp": [
datetime.now(),
],
"created": [
datetime.now(),
],
"conv_rate": [1.0],
"acc_rate": [1.0],
"avg_daily_trips": [1000],
}
)
print(event_df)
store.push("driver_stats_push_source", event_df, to=PushMode.ONLINE_AND_OFFLINE)
get_online_features
オンラインストアから現在時刻をもとに特徴量を検索する際には、get_online_featuresを使用します。
returned_features = store.get_online_features(
features=features_to_fetch,
entity_rows=entity_rows,
).to_dict()
Example 2 : Fraud detection
次は、ローカルではなくGCPを使用した例を触ってみたいと思います。
こちらは不正検知システムのデモになっています。
概要
ここでは下記の処理をやっていきます。
- 準備
- GCPプロジェクトのセットアップ
- データセットの準備
- Feature Storeのセットアップ
- モデルの学習
今回のデータセットは銀行の送金の疑似データで、それぞれのやり取りにis_fraud(詐欺)というラベルがついています。
今回はこのデータを使って、詐欺のトランザクションを検知することを考えたいと思います。
準備
今回はデフォルトで用意されているデータではなく、外部のデータセットを使用するので、その準備をします。
GCPプロジェクトのセットアップ
GCPを使用するようなチュートリアルとなっているので、それに従って作成していきます。 必要な準備は下記のようになっているようです。
- projectの設定
- gcsのバケットの作成位
- bqのデータセットの作成
- service account(キー)の設定
- Cloud datastoreの設定
データセットの確認
今回はBigQueryに格納されているデモ用のデータを使用します。中のデータの確認をしてみると、こんな感じのデータが入っているようです。
select * from feast-oss.fraud_tutorial.transactions limit 1000
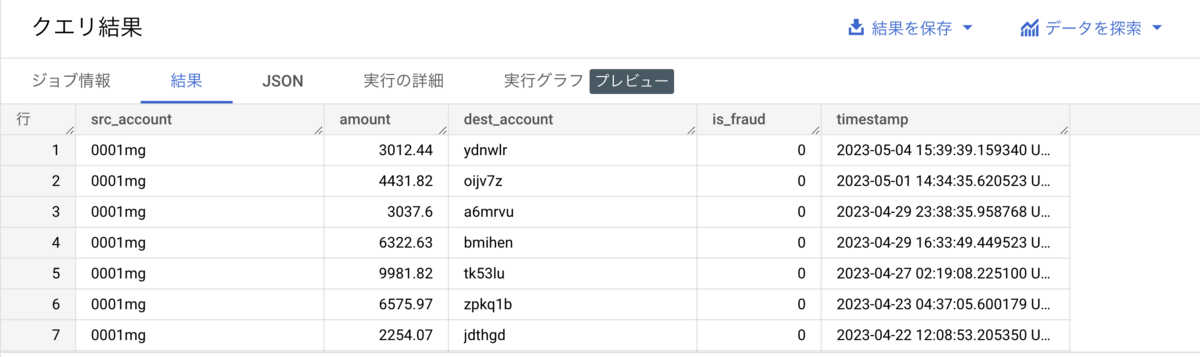
誰から誰に対していくら送金したかのデータが与えられるような状況が想定されているようですね。
このテーブルから特徴量を作成してみます。
from datetime import datetime, timedelta from google.cloud import bigquery import time def generate_user_count_features(aggregation_end_date): table_id = f"{PROJECT_ID}.{BIGQUERY_DATASET_NAME}.user_count_transactions_7d" client = bigquery.Client() job_config = bigquery.QueryJobConfig(destination=table_id, write_disposition='WRITE_APPEND') aggregation_start_date = datetime.now() - timedelta(days=7) sql = f""" SELECT src_account AS user_id, COUNT(*) AS transaction_count_7d, timestamp'{aggregation_end_date.isoformat()}' AS feature_timestamp FROM feast-oss.fraud_tutorial.transactions WHERE timestamp BETWEEN TIMESTAMP('{aggregation_start_date.isoformat()}') AND TIMESTAMP('{aggregation_end_date.isoformat()}') GROUP BY user_id """ query_job = client.query(sql, job_config=job_config) query_job.result() print(f"Generated features as of {aggregation_end_date.isoformat()}") def backfill_features(earliest_aggregation_end_date, interval, num_iterations): aggregation_end_date = earliest_aggregation_end_date for _ in range(num_iterations): generate_user_count_features(aggregation_end_date=aggregation_end_date) time.sleep(1) aggregation_end_date += interval if __name__ == '__main__': backfill_features( earliest_aggregation_end_date=datetime.now() - timedelta(days=7), interval=timedelta(days=1), num_iterations=8 )
このような形で特徴量を設定しているようです。
select * from fraud_detection_data.user_count_transactions_7d limit 1000
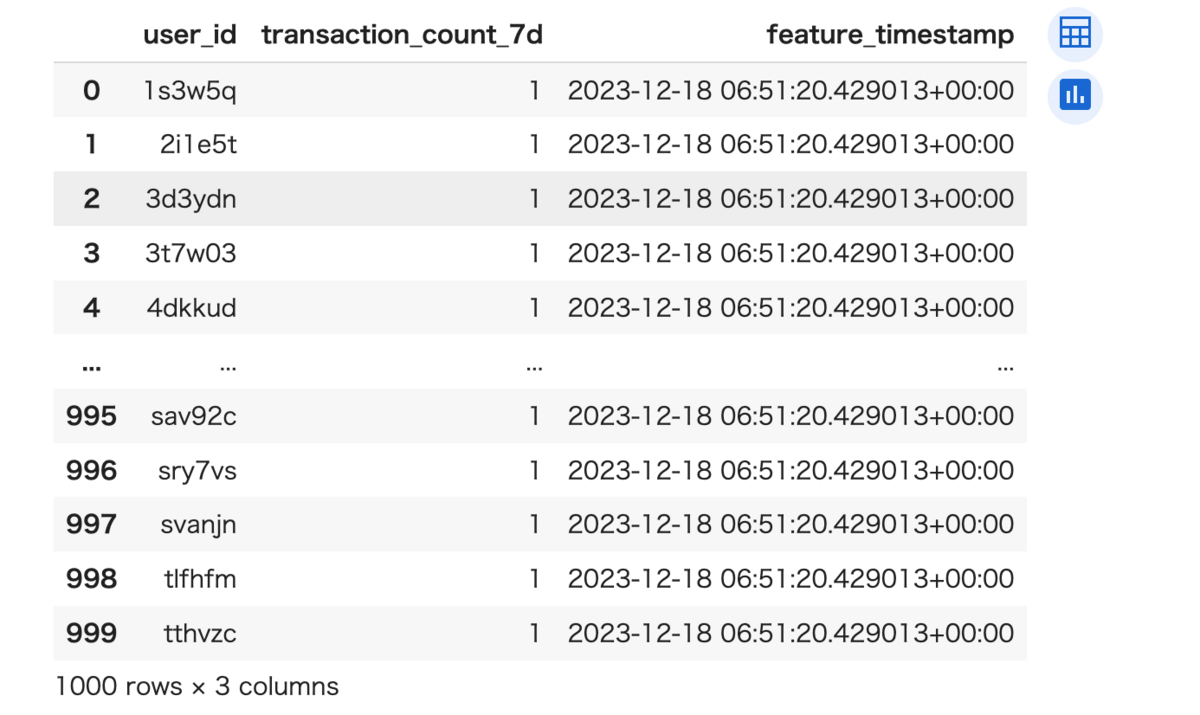
Feature Storeのセットアップ
ここまではBigQueryに入っているデータの確認でした。 データの確認できたところで、本題のFeature Storeのセットアップをしていきます。
下記のようなfraud_features.pyでスキーマを定義していきます。
from datetime import timedelta
from feast import BigQuerySource, FeatureView, Entity, ValueType
# Add an entity for users
user_entity = Entity(
name="user_id",
description="A user that has executed a transaction or received a transaction",
value_type=ValueType.STRING
)
# Add a FeatureView based on our new table
driver_stats_fv = FeatureView(
name="user_transaction_count_7d",
entities=[user_entity],
ttl=timedelta(weeks=1),
source=BigQuerySource(
table=f"feast-example.fraud_detection_data.user_count_transactions_7d",
timestamp_field="feature_timestamp"))
# Add two FeatureViews based on existing tables in BigQuery
user_account_fv = FeatureView(
name="user_account_features",
entities=[user_entity],
ttl=timedelta(weeks=52),
source=BigQuerySource(
table=f"feast-oss.fraud_tutorial.user_account_features",
timestamp_field="feature_timestamp"))
user_has_fraudulent_transactions_fv = FeatureView(
name="user_has_fraudulent_transactions",
entities=[user_entity],
ttl=timedelta(weeks=52),
source=BigQuerySource(
table=f"feast-oss.fraud_tutorial.user_has_fraudulent_transactions",
timestamp_field="feature_timestamp"))
これで、BigQueryに入っているデータをFeastから呼び出すことができるようになります。
モデルの学習
このラベルを当てる問題を考えます。
from datetime import datetime, timedelta from feast import FeatureStore # Initialize a FeatureStore with our current repository's configurations store = FeatureStore(repo_path=".") # Get training data now = datetime.now() two_days_ago = datetime.now() - timedelta(days=2) training_data = store.get_historical_features( entity_df=f""" select src_account as user_id, timestamp as event_timestamp, is_fraud from feast-oss.fraud_tutorial.transactions where timestamp between timestamp('{two_days_ago.isoformat()}') and timestamp('{now.isoformat()}')""", features=[ "user_transaction_count_7d:transaction_count_7d", "user_account_features:credit_score", "user_account_features:account_age_days", "user_account_features:user_has_2fa_installed", "user_has_fraudulent_transactions:user_has_fraudulent_transactions_7d" ], full_feature_names=True ).to_df()
entity_dfで、予測対象のuser_idと正解ラベル(is_fraud)を取得し、そこに紐づく特徴量を呼び出しています。
ここでポイントは紐づけを行うjoinの処理がどこにも書かれていないことでしょう。
このように、特徴量のjoin処理はすべてFeastで行われ、使用者側はEntityとtimestampだけを気にするようになっています。
学習に関しては、この例ではLogistic regressionを使用しているようです。
from sklearn.linear_model import LinearRegression # Drop stray nulls training_data.dropna(inplace=True) # Select training matrices X = training_data[[ "user_transaction_count_7d__transaction_count_7d", "user_account_features__credit_score", "user_account_features__account_age_days", "user_account_features__user_has_2fa_installed", "user_has_fraudulent_transactions__user_has_fraudulent_transactions_7d" ]] y = training_data["is_fraud"] # Train a simple SVC model model = LinearRegression() model.fit(X, y)
あとはこれにデータを与えれば推論できます。このあたりは普通の機械学習モデルと同じですね。
# Get first two rows of training data samples = X.iloc[:2] # Make a test prediction model.predict(samples) # array([0.05070566, 0.05395784])
以上、GCPを使用したときのFeature Storeの使い方を確認してみました。GCPのサービスを使いながらFeastも動かせた気がします。*2
使用したリポジトリ
今回使用したコードはこちらのリポジトリにアップしてあります。
- example_1
- example_2
参考文献
今回、主にFeastのドキュメントを参考にさせていただきました。
結構ちゃんとドキュメントが書いてあるので、こちらを参照することをおすすめします。
また、この記事を書くにあたって下記の文献を参考にさせていただきました。
感想
今回はFeature StoreのOSSの一つであるFeastを使ってみました。 オンライン学習・推論をいい感じにやろうとするとFeature Storeなどが便利であるのは理解できますし、オンライン・オフラインストアの構成を隠蔽できるという意味では確かに良いんだろうなとは感じました。 実際に導入するとなったらマネージド・サービスなどで管理を簡単にしたら、オンライン学習・推論などでも全然使えそうだなと感じました。
珍しくこういうMLOpsの技術を試してみましたが意外と楽しかったので、また何か機会があれば別のMLOps関連のサービスも触ってみたいと思います。
*1:https://www.nogawanogawa.com/entry/feature_store#WhatFeature-Store%E3%81%A8%E3%81%AF%E3%81%AA%E3%81%AB%E3%82%82%E3%81%AE%E3%81%8B
*2:実際にはこの後にモデルをデプロイしたりと色々やることがあるんですが、アドベントカレンダーに間に合いそうになかったのでここまでとしています