
この記事は「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020の19日目の記事です。
こちらのアドベントカレンダーでは「情報検索:検索エンジンの実装と評価」(Buttcher本)を読んで、1日1章ずつまとめるといった内容になっています。

- 発売日: 2020/10/30
- メディア: 単行本
本日は、14章の「並列情報検索」について勉強していきます。
なるべく、自分の理解のために噛み砕いてこの記事を書いたつもりですが、間違っているところを見つけた方はDMとかでこっそり教えていただけれると嬉しいです。
背景:データの肥大化
Webサービスのような大規模にドキュメントを扱うシステムを考えると、現在のデータ量はテラバイト〜ペタバイト、場合によってはエクサバイトのスケールにも及ぶかと思います。 扱うデータ量が増大すれば、検索にかかる計算量も増大し、検索にかかる所要時間が増大する恐れがあります。 この規模のデータを取り扱うシステムでシステム全体を安定稼働させることを考えると、検索に関わるシステムを分散処理によってスケールアウトしていくことが必要になってくる場合があります。
検索のスケールアウト
ドキュメント分割
検索対象となるドキュメント群をノードごとに分担することを考えるのがドキュメント分割です。 最終的に、ドキュメント分割では小さな検索システムを多数寄せ集め、それらの結果を総合することで大規模な検索を実現します。

ドキュメント分割の際の振る舞いとしては、まず、受付サーバーが検索に関するクエリを受け取り、そのクエリをドキュメントを分割したノード全てに対して転送します。 各検索ノードは、自分が担当するドキュメント群に対するクエリの結果を受付サーバーに送り返し、受付サーバーですべての応答の結果を合わせてユーザーに返す、といった流れになります。
ドキュメント分割の最大のメリットは、概念のシンプルさだとしています。 ドキュメント分割によって単純に分割するだけでも、各ノードにおいては検索対象のドキュメント数は少なくなり、その分インデックスのサイズも小さくなります。 そのため、個別のノードにおけるデータ量・処理速度の観点で分散処理によって効率化が可能になります。
ターム分割
もともと1つのノードが担当していた検索に使用されるタームを、ノードごとに分割することを考えるのがターム分割です。

各ノードが異なるクエリタームに関する処理を担当するため、クエリに含まれるタームを担当するノードに対してクエリを転送して、その結果をあわせることで可能になります。 この方法では、単一のノードに含まれるタームの量は少なくなるためノードレベルでは処理は軽量化し、実際に動作するノードはドキュメント分割よりも少ないためより効率的と考えられます。
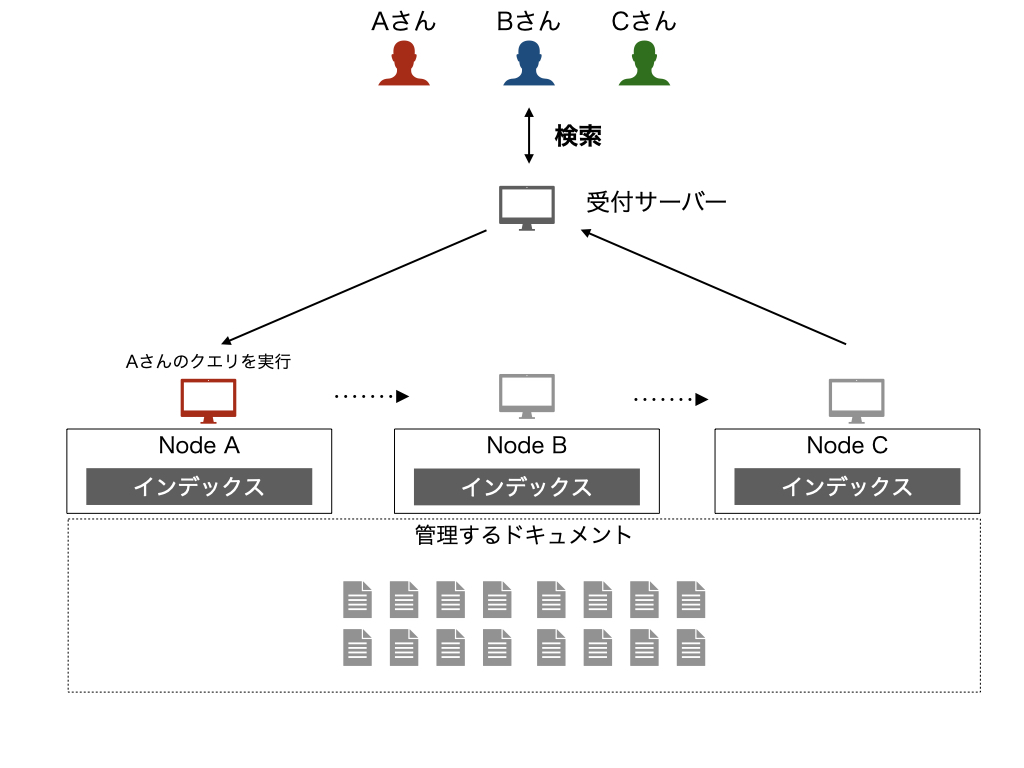
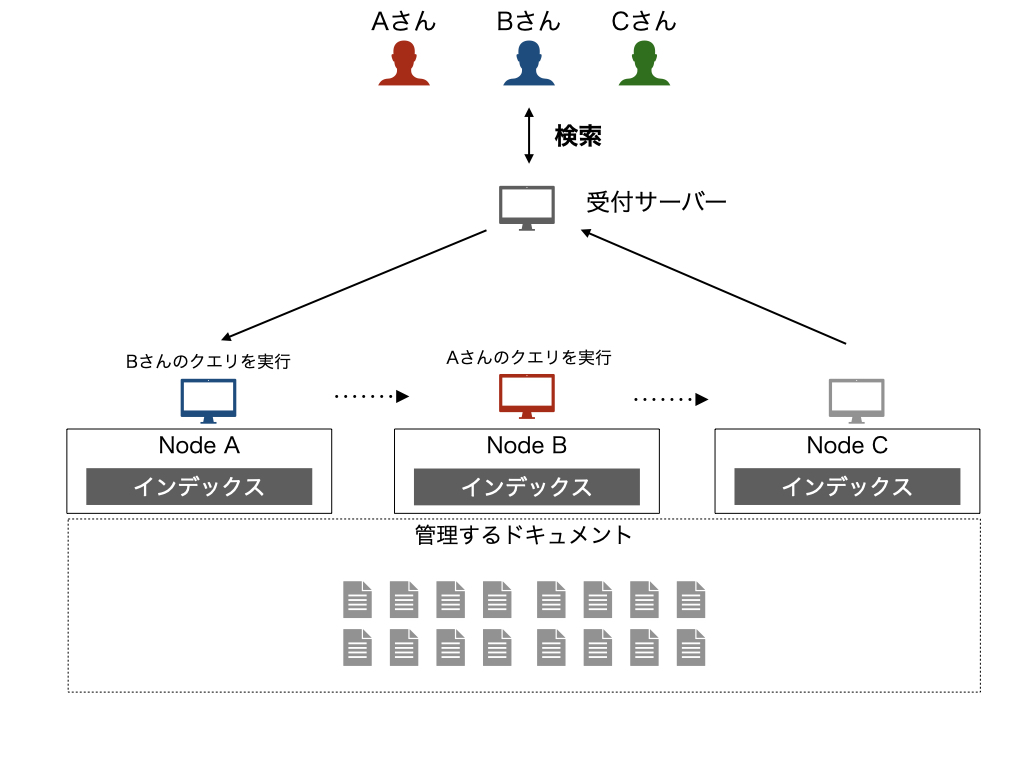
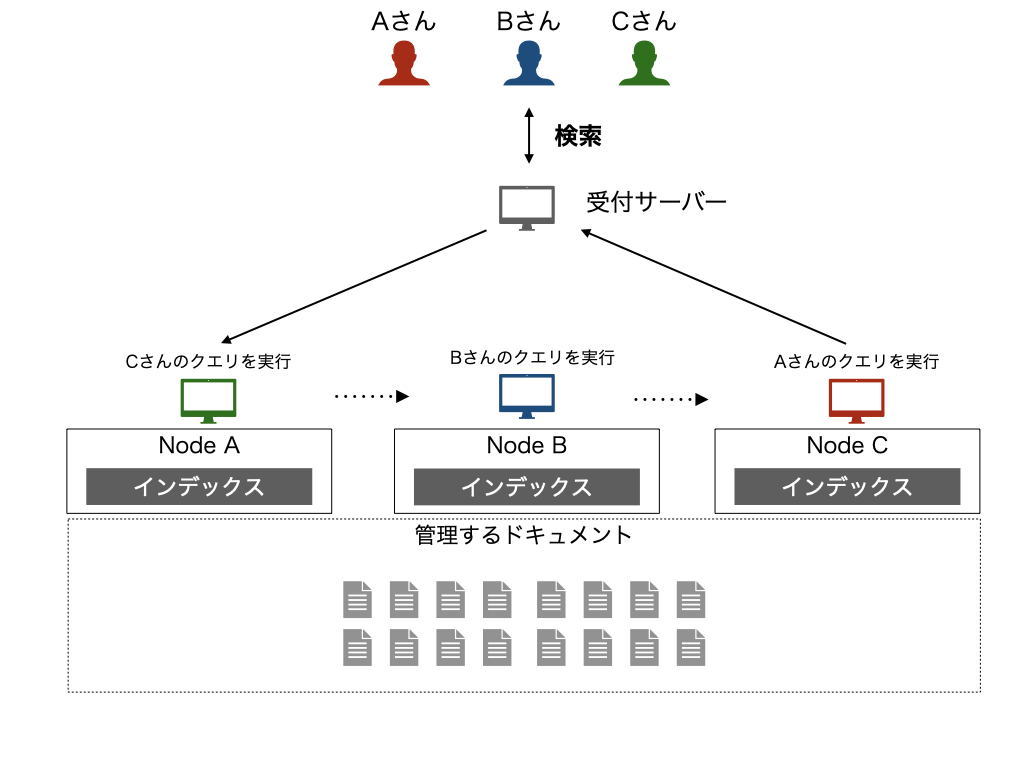
ただし、レイテンシという意味では単一のノードで実行している場合とそれほど改善はしません。 稼働するノードを振り分けることができるので、負荷分散になり、スループットの向上は期待できます。
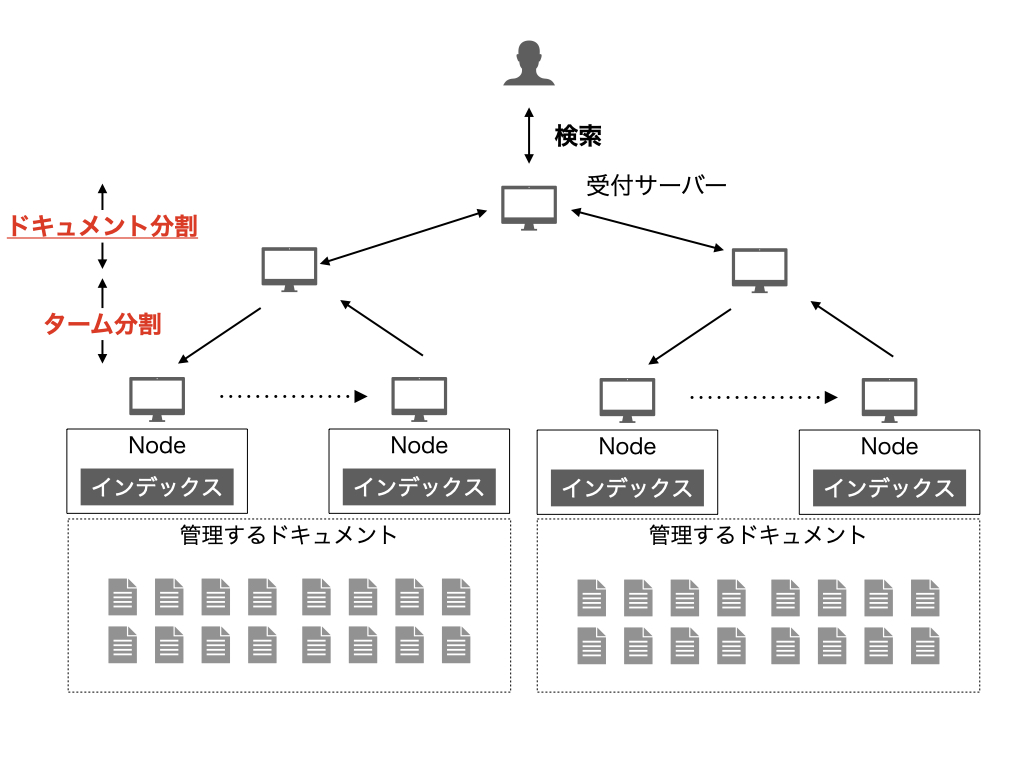
また、ドキュメント分割とターム分割は、組み合わせて考えることもなされています。 下記のようにコレクションをドキュメント分割し、分割したコレクションに対してターム分割するようなイメージになります。
具体例:Elasticsearchではどうやってる?
概念的な話はなんとなくわかったので、ここではちょっと脱線して、実際に動くものではどうなってるのかについて確認してみたいと思います。
検索エンジンの中で、私がまともに使ったことがあるのがElasticsearchだけなので、そちらで分散処理に関してどのように対応しているのかについて確認してみたいと思います。
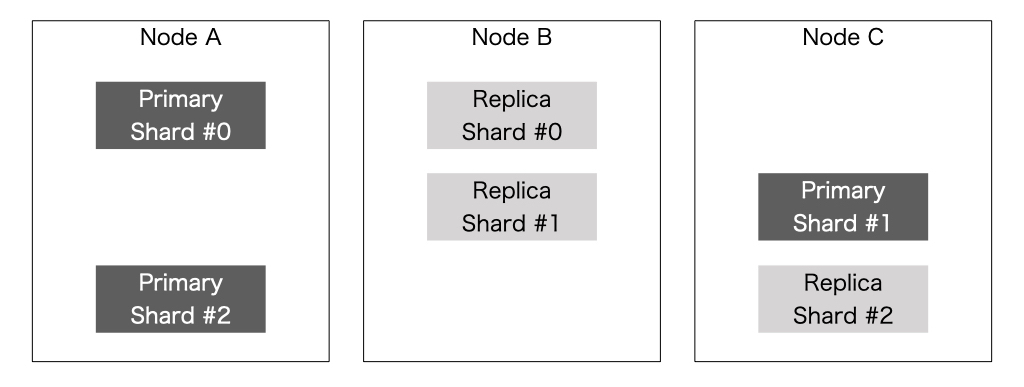
ElasticsearchにはShardという概念があります。 これは、indexを分割したものを表しており、ここでいうドキュメント分割されたものに当たるかと思います。 Elasticsearchでは、Shardを分割することで検索の処理を並列に実行することができるようになっているため、検索処理をスケールアウトすることで高速化できるようになっているんですね。
その他、考慮する観点
検索を含めたシステムとして考えた際には、検索のシステムに何かしらの障害が発生した際にも、動作し続けるような設計をしておく必要があります。 具体的には、 耐障害性という点においてデータを分散して管理することはメリットを持ちます。 上記のようにドキュメント分割をした際にはレプリケーションと組み合わせることによって、単一のノードが障害になった際にも他のノードだけでサービスを継続することが可能になるように配置することができます。

検索を高速化するという点と同時に、冗長性についても考慮する観点として挙げられます。
検索に関わるその他の分散処理
ここまで、「検索」処理をどのように分散処理するかについて紹介しました。 ただ、本書では検索エンジンの内部で行っているのは検索処理だけではなく、
- インデックスの作成・更新
- 重複ドキュメントの検知
- ドキュメントコレクション内のリンク解析
など様々あるとしています。
そのため、検索以外の負荷の大きい処理についても分散処理する事が望まれます。 これらの負荷の大きい処理を分散させる際には、分散処理フレームワークが使用されたりします。
検索に関わる処理のケースでは、例えば下記のようなパターンが適用可能なことがあるかと思います。 すべての文書に対して同一の処理(例:ドキュメント内の単語ごとの出現回数のカウント)を行い、ドキュメント全体で集計処理を行うような処理が発生することがあります。
こういった処理は、MapReduceのような分散処理でスケールアウトすることが可能になったりします。 詳細は割愛しますが、データをノードの数だけ分割して各ノードで独立に計算し、計算した結果を集めることで高速化したりします。 何でもかんでも高速化するとは限りませんが、個々の処理が他のデータに依存おらず、演算ボトルネックであるようなときには強く効果を発揮するように、経験的には思っています。

このような処理を自前で分散処理を記述して高速化しようとすると、分散処理フレームワークを使用するのが一般的かと思われます。 2020年現在だと、HadoopやSparkのようなものが一般的なように思いますので、その辺を活用して実装していくことになるのでしょう。
参考文献
下記の文献を参考にさせていただきました。

Elasticsearch実践ガイド impress top gearシリーズ
- 作者:惣道 哲也
- 発売日: 2018/06/15
- メディア: Kindle版
感想
今回の部分は、検索技術というよりも検索システムとしてどういったことに気をつけないといけないか、のような話だったかと思います。
検索アルゴリズムを工夫してより情報要求が満たされるようにするのも検索システムでの工夫点ですが、こういったシステム全体の処理効率を上げることも大事なポイントになりますね。 データの規模が小さいうちはそんなに気にならないと思いますが、データが大きいとこういった観点も結構問題になるんだろうなと思いました。 検索エンジンを触るときは、こういうところにも気を配らないといけないんですね。勉強になりました。
諸事情により投稿が遅れましたが、なんとかクリスマスに間に合ってよかったです。本書を読む際の参考になれば幸いです。
- 発売日: 2020/10/30
- メディア: 単行本