この記事は「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020の12日目の記事です。
こちらのアドベントカレンダーでは「情報検索:検索エンジンの実装と評価」(Buttcher本)を読んで、1日1章ずつまとめるといった内容になっています。

- 発売日: 2020/10/30
- メディア: 単行本
本日は、10章の「分類とフィルタ」について勉強していきます。
なるべく、自分の理解のために噛み砕いてこの記事を書いたつもりですが、間違っているところを見つけた方はDMとかでこっそり教えていただけれると嬉しいです。
背景:情報要求
情報検索システムについて考える際、ユーザーはなんらかの情報要求(何を検索したいかという要求)を持っています。 このとき、ユーザーが持つ"情報要求"はタームに関するものだけではなく、もっと広い意味を持つことがあります。
- 日本語で書かれた文書がほしい
- 新しくニュースサイトに追加された記事を継続的に通知したい
- スパムメールを除いた自分に関連するメールだけを確認したい
このように、クエリとして与えることのできるターム以外の観点でもユーザーは情報要求を持つことがあります。 こうした情報要求は、クエリとは別に考える必要があり、通常クエリだけで指定することは困難です。 このような情報要求を満たすために、分類(categorization)やフィルタ(filtering)が行われます。
これらの分類は、時間をかけてルールベースで行うことも可能ではある一方、非常に非効率であるという問題もあります。 そのため、機械学習をはじめとする、自動で分類・フィルタするアプローチが有望と考えられます。 こうした技術も、情報要求を満たすという点から考えて検索の一部であり、これらを検索システムに適用していくことは非常に価値のあることと考えられます。
分類とフィルタ
9章までで扱ってきた検索という機能と、10章で取り扱う分類・フィルタは類似点もあるが、いくつかの点で異なっています。
ここで、分類に関する定義を確認します。
分類(categorization)は, 何らかの情報要求を満たすためにドキュメントをラベル付けするプロセスである. 情報検索:検索エンジンの実装と評価
フィルタの定義についても確認します。
フィルタ(filtering)は, なんらかの定常的な情報要求に応じて継続的にドキュメントを評価するプロセスである. 情報検索:検索エンジンの実装と評価
検索も分類・フィルタリングも、情報要求を満たすためのプロセスであるという点については共通しています。 ただし、検索というプロセスが与えられたクエリという形の情報要求をもとにドキュメントについて関連する・しないのラベルをつけるのに対し、分類・フィルタはドキュメントが属するカテゴリを探索し、それが情報要求を満たすかを判定します。 そのため、分類・フィルタに関しては8章までで取り扱うような検索の手法では期待する応答を得ることが難しくなるという点で異なっています。
ここから簡単な例に沿ってどのように分類・フィルタを行うか考えます。
例1:ニュースフィード
今、ニュースフィードについて、ユーザーにとって有益な情報を表示することを考えます。*1
事前にユーザーの興味のある分野がわかっているとすると、一見するとこれはニュース記事の中からユーザーの興味のあるタームを用いてクエリをかける検索処理に見えなくもありません。
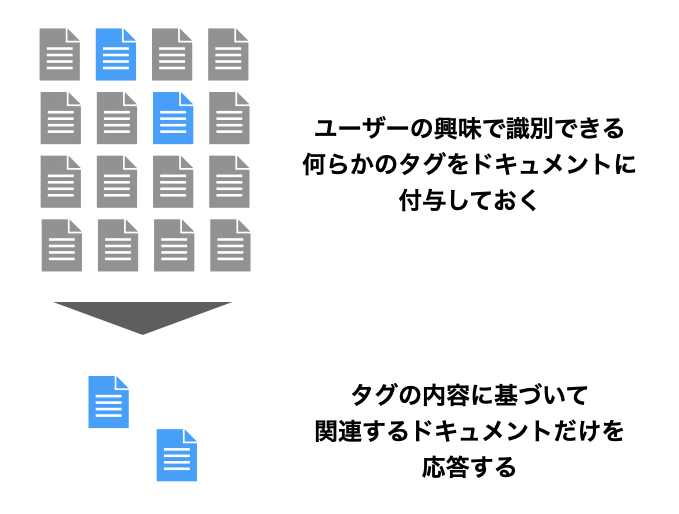
しかし、この状況下では検索対象となるドキュメントがいつ手に入るかわからないという制約が入ります。 ドキュメントが得られてからユーザーが検索するまでに十分な時間がない状況下では、ユーザーに関連する・関連しないのラベルをつけていく事が間に合わないことが考えられます。
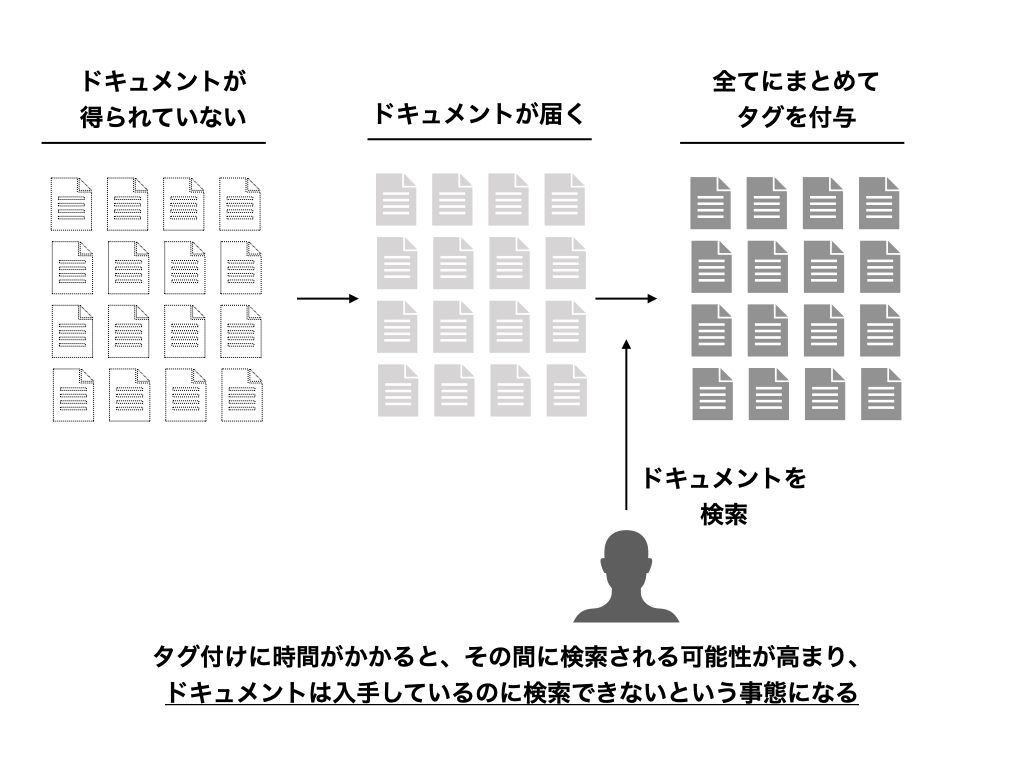
ここで、この問題についてもう少し詳細に考えます。 いま問題になっているのは検索対象となるドキュメントすべてが集まりきるのがギリギリになってしまうケースです。 対象のドキュメントが集まりきってからタグ付けを開始していてはその分タグ付けの完了も遅くなってしまします。 このようになってしまうと、なかなか現実的にユーザーに応答するのは難しいかもしれません。
フィルタによるアプローチでは、新しいドキュメントがコレクションに追加されたタイミングで即座にラベルを付与することを考えます。

このように、ドキュメントが入手できたタイミングでタグ付の処理が実行されれば、ユーザーの検索に応答することが可能になります。
例2:文献調査
今度は、何かしらの文献(例、裁判の判例など)を見つけ出すことを考えます。 検索システムのユーザーは自身の要求に基づいてクエリを作成しますが、クエリには含まれない情報要求が考えられます。 ここでは、国内・海外問わず裁判の記録の中から、「国内での判例に限って」文献を調べたいとします。 この際、暗黙に含まれる情報要求には「ドキュメントが日本語で記述されている事」が含まれると予想されます。
実はこの情報要求は厄介で、それぞれのドキュメントが何語で書かれているかを加味して応答する必要があります。 これを検索システムに入力されるクエリだけを使用して行うことは難しく、ドキュメントが何語で記述されているかについて事前にラベル付けする必要があります。
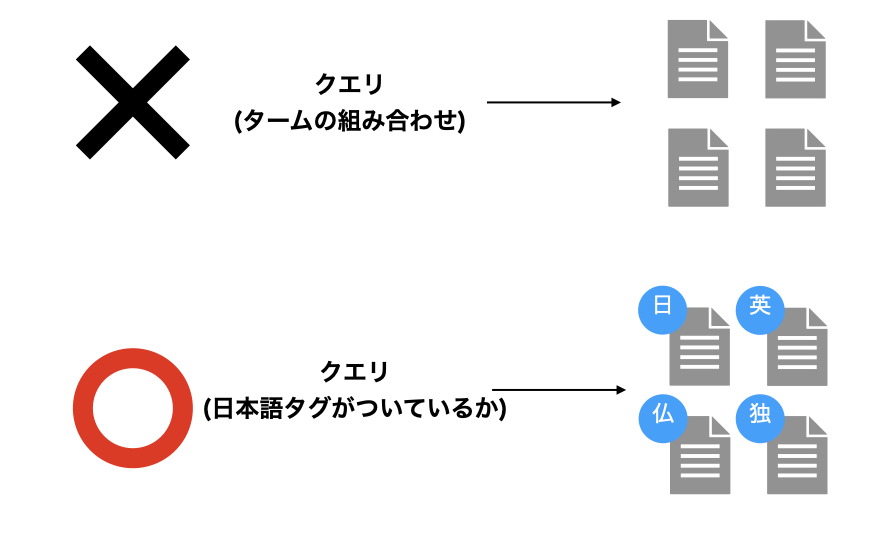
事前にドキュメントに対して記述されている言語のタグを付与しておけば、対象の言語のドキュメントだけを応答することは非常に容易になります。
分類・フィルタを考慮する
ここまでで、検索システムにおける分類・フィルタの必要性とその大まかな手法について紹介しました。 これらの内容を踏まえたとき、システムとして必要になる機能がいくつか考えられると思われます。
分類やフィルタを検討する場合、素朴な検索システムに加えて必要になるのは
- ユーザーからのフィードバックを分類器に適用するプロセス
- 過去のドキュメントを使用して分類器を構築するパイプライン
かと思われます。 先に書いたように、ドキュメントがいつ追加されるか不明で、ユーザーが検索するまでに検索に伴う準備の処理がすべて完了する必要がある場合には、現実的な時間内で検索できる準備を整えることが可能な処理系を構築する必要があります。
そのため、オンラインでのクエリ処理に加えてバックグラウンドで分類・フィルタをうまく組み合わせることが必要になってきます。 だいたいこのような形でしょうか。
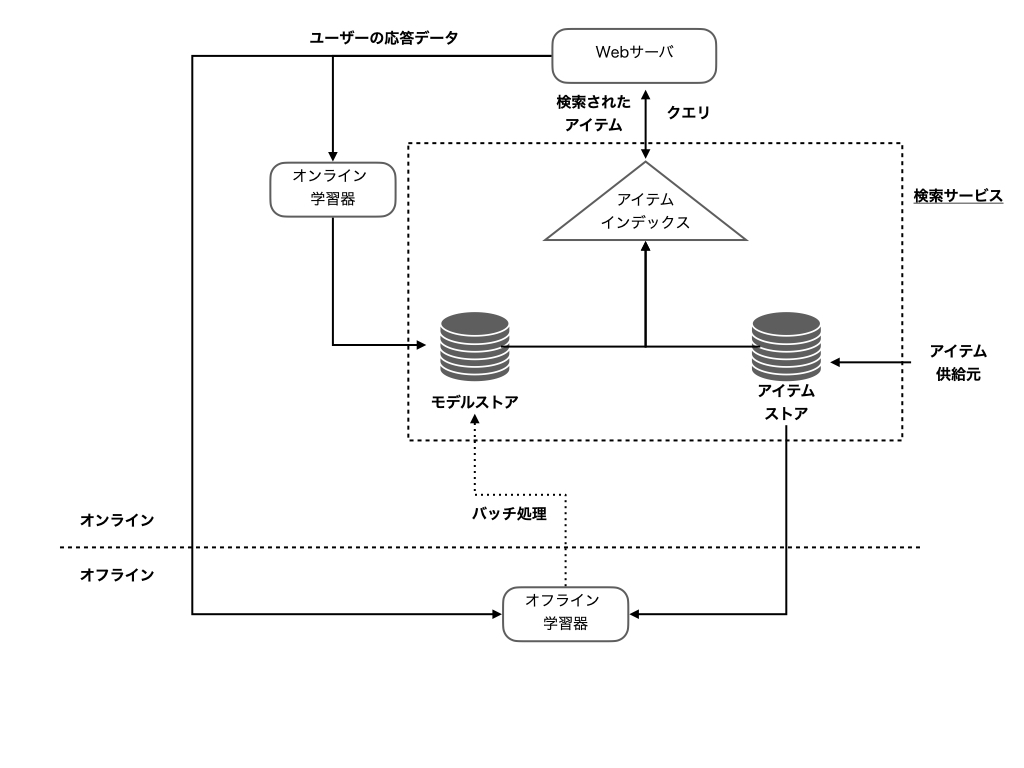
ラベル付けをオンラインあるいはオフラインで何かしらのラベル付けを行うモデルを構築し、そのモデルを用いてラベル付けしていけば、急なドキュメントの追加やドキュメントに対して自動的にラベルを付与するということに対応することができるようになるでしょう。
分類に使用される主な機械学習手法
ドキュメントに対してラベルを付与することで満たすことができる情報要求があることを、ここまでで確認できたかと思います。 分類やフィルタは、長い時間をかければアルゴリズムを考えて適用することもできるかもしれませんが、その作業負荷と検索条件の時間変化を考えると現実的ではなく、機械学習を使用するアプローチが一般的と考えられます。
最終的にドキュメントに何らかのラベルを割り振ることが目的ではあるものの、そのためのアプローチは様々です。 本書で紹介されている具体的な手法について簡単に確認してみたいと思います。
確率的格付け器
堅苦しい名前はついていますが、要するに「特徴をもとにドキュメントがクラスに属する確率を推定」するものです。 「特徴」にも様々ありますが、ここでは自然言語処理の文脈で使用される特徴全般をご想像いただければと思います。
簡単な例として、ドキュメントを分類することを考えます。 ドキュメントがクラスAとクラスB のどちらかに属するとわかっているとき、ドキュメントの内容からクラスA/Bを推定するようなタスクを考えます。
確率的格付け器では、
- 個々の特徴の分布に基づいてクラスに所属する確率を推定
- 推定された個々の特徴ごとの分類確率を統合して、最終的に文書がどのクラスに属するかを推定
といった流れで分類を考えます。
1.は、特定のタームが文中に含まれるか(0 or 1)、文中に何回含まれるか(0 ~ n )などの特徴に対して、クラスの分類にどの程度偏りがあるかを確認します。 これに続いて、2.では個別の特徴をナイーブ・ベイズやロジスティック回帰などで分類していくことを想像していただければと思います。
線形格付け器
今度はドキュメントについて、線形に分類していく方法を考えます。 各ドキュメントについて特徴空間で考え、各ドキュメントはそれぞれ個別のn次元の特徴ベクトルで表現されるものとします。 このn次元空間に対して、クラスを分離するような平面でクラスを分ける方法が線形格付け器でやることになります。
具体的には
- パーセプトロンアルゴリズム
- SVM
などが代表的な手法になります。
類似性に基づいた格付け器
ドキュメント間の類似性に着目してタグ付けしていくアプローチもあります。 前提となる考え方としては、
似たドキュメントは似ていないものよりも同じカテゴリに属する可能性が高い 情報検索:検索エンジンの実装と評価
といったところになります。 異なる2つのドキュメントに対してそれらの類似度を算出することができれば、類似度を組み合わせてドキュメントを分類することが可能になります。
類似性について評価する方法としては
- ロッキオ法
- メモリベース法
などが紹介されています。
ロッキオ法については、コレクションの重心であるような代理ドキュメントを仮想的に定義し、代理ドキュメントと対象のドキュメントの間の類似性によって格付けを行っていきます。
メモリベース法は、個々のドキュメント間の類似度に基づいて(k最近傍の探索などによって)格付けを行っていきます。
カーネル法
線形格付け器では、分離超断面が定義できないケースがあり、その場合には何らかの変換を行わないとうまく分離できません。
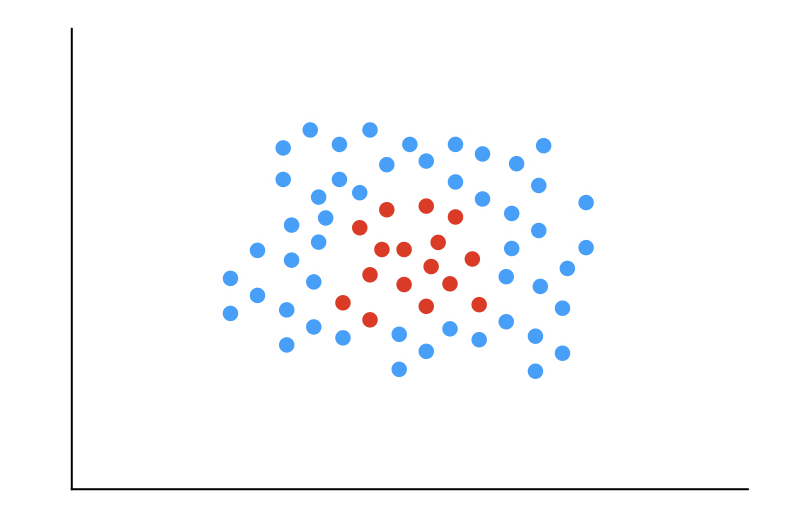
このようなケースでは、特徴量空間に対して正例と不例を分離するような特徴量を追加して次元を拡張する事で対応することができます。
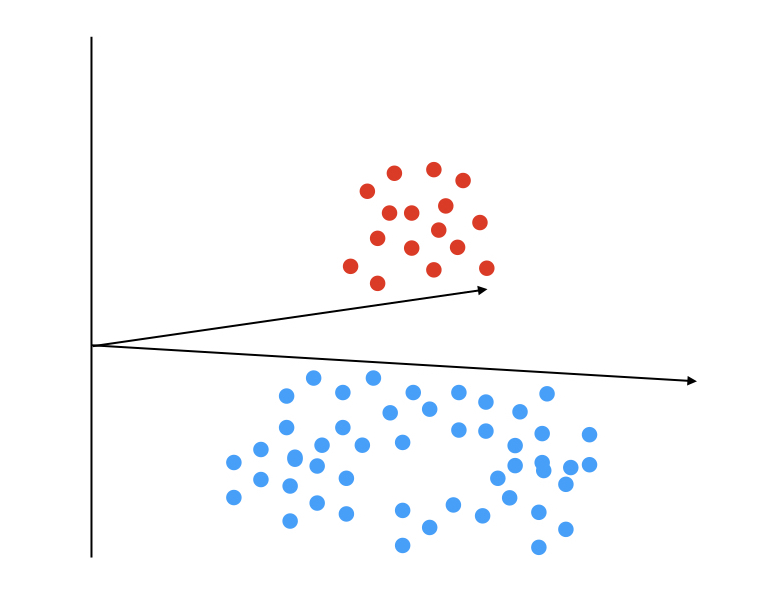
この次元を増やす部分でカーネル関数というものを使用します。 カーネル関数は様々考案されており、カーネル法を使用する代表例であるSVMに関しては、SVMのパッケージにカーネル関数が含められているのでご使用のライブラリをご確認ください。
情報理論的モデル
ここまで見てきた内容では、単一の分類モデルを考えていました。 複数のモデルを同時に作成し、それらを比較して最も良いと思われるモデルを選択する方法もあります。 ただし、この場合複数のモデルが真の確率からどれだけ乖離しているかを評価する必要がありますが、現実には真の確率は手に入らないケースが多いかと思われます。
そのため、データ圧縮モデルによって未知のドキュメントについての尤度比を推定することで分類したり、訓練データのラベルを一番良くモデル化できているモデルを採用するなどのアプローチが考えられます。
逐次圧縮モデルは、ドキュメントに含まれる文字を逐次的に読み込んで、クラスに対する所属確率を推定していく方法のようです。 具体例として本書では、クラスの推定値がドキュメントに含まれる文字の系列に対してマルコフ連鎖するとした動的マルコフ圧縮(DMC)が紹介されています。 *2
決定木によるクラス分類の方法も考えられます。 分類対象のドキュメントを部分集合に分割し、それらの部分集合に対して更に部分集合に分割する、という処理を繰り返し、最終的に得た小さな部分集合に対して分類するといったものになります。
参考文献
下記の文献を参考にさせていただきました。
- 発売日: 2020/10/30
- メディア: 単行本

- 作者:Agarwal,Deepak K.,Chen,Bee‐Chung
- 発売日: 2018/04/21
- メディア: 単行本
感想
アドベントカレンダーの枠が空いていたので、勉強がてら10章も記事書いてみました。 今回も、内容についてはだいぶ噛み砕いて(+かなりの分量を端折って)書いてみたつもりです。*3 本書ではBM25を使用した分類・フィルタを紹介するなど、他でなかなか見ない議論が書いてあったりするので、興味を持った方は読んでみてはいかがでしょうか?
本章は、一見すると検索とは若干異なる話に思いました。 ただ、情報要求を満たすためのプロセスという点では検索と同じですし、実際には分類やフィルタが検索に組み込まれて使用されるケースが多いと考えると、検索システムの一部として考えるのは納得でした。
勉強になりました。