ここ数ヶ月くらい、推薦システムにおけるNNの活用というテーマで論文をちょこちょこ読んでいました。 推薦システムにNNを適用・応用するという守備範囲も広いテーマではありますが、せっかく良い機会なので自分用にまとめてみたいと思います。
理解が曖昧なところもあり、マサカリが飛んできそうな気配がプンプンしますが、がんばって書いてみたいと思います。マサカリコワイ...
前提知識
ニューラルネットワークの推薦システムへの適用について見ていく前に、前提として一般的な推薦システムで広く使用される協調フィルタリング系の推薦についてかんたんに見ていきたいと思います。
協調フィルタリング
推薦システムに使用される有名なアルゴリズムとして、協調フィルタリングがあります。 完全に個人的な理解ですが、協調フィルタリングのアイデアは似た傾向を持つユーザーは似たようなアイテムを好むだろうという考えに基づいているように思います。
例として、下記のような状況を考えてみます。 縦方向にユーザー、横方向にアイテムを示したマトリクスを考えます。 マトリクスの要素はユーザーによるアイテムに対する評価になっています。
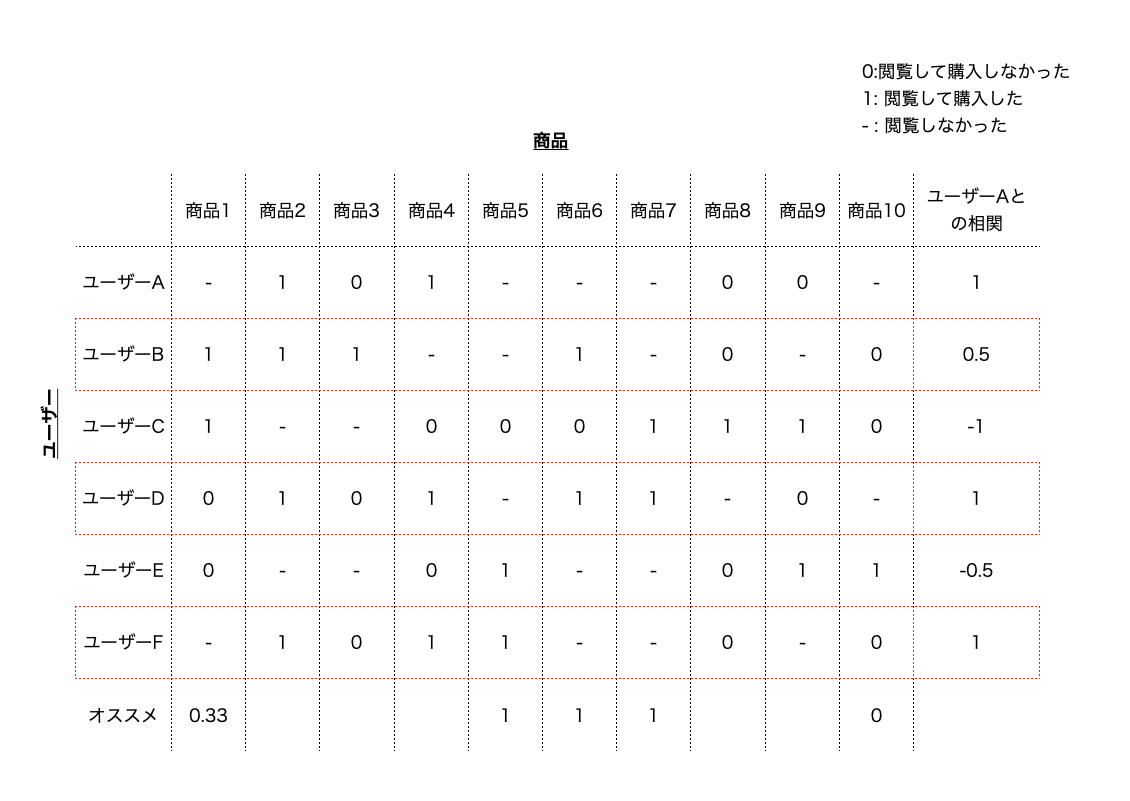
上記のようなデータが与えられたときに、ユーザーXに対してどのアイテムをおすすめするのが最も妥当かを協調フィルタリングを用いて考えます。
ステップとしては大体2段階に分けられて
- ユーザーの類似度の算出
- 類似するユーザーの行動に基づいて、アイテムの推定レイティングを算出
ユーザーの類似度については、例えばピアソンの相関係数を使用して下記のような式を用いて算出する事ができます。
これであるユーザーAに着目したとき、他のユーザーがユーザーAにどれだけ似ているかを数値化できました。
次に、似ているユーザーのアイテムに対する評価を用いて、ユーザーXにおすすめするべきアイテムを求めます。
上記の式については、別途記事を書きましたのでそちらをご参照ください。
Matrix Factorization
さて、協調フィルタリングは計算効率があまり良いとは言えず、ユーザー数・アイテム数の増大に伴って計算時間が増大します。 ひどいときには、現実的な時間で計算が終わらなくなる恐れがあります。
そこで計算効率を良くするのが次元削減の手法である行列分解(Matrix Factorization)です。 上の協調フィルタリングの例では、ユーザーとアイテムのマトリクスを中心に考えていました。 そして、ユーザーとアイテムの数が増えるほどこの行列のサイズは掛け算式に大きくなります。
ここで、この行列を長方形の2つの行列の掛け算で表現することを考えます。
ここでは、ユーザーiにとってアイテムjの推定レイティング、
はそれぞれユーザー・アイテムに関する潜在因子を表す行列になっています。
この変形により
の行列を見つければ良い事になります。
協調フィルタリングで計算する必要があった推定レイティングが
だったのに対して、Matrix Factrizationで求める必要があるパラメータは
,
となり、(Lが
より小さい限り)求めなければいけない要素数は小さくなります。
このようなについて、ALSやSGDを使用して近似的に解を求めることで推定レイティングを効率よく計算することができるようにしたのがMatrix Factrizationといえます。
Factorization Machine
Matrix Factorizationのあとに発表された優れたアルゴリズムがFactorization Machineです。 Matrix Factorizationではあくまで行列の掛け算で協調フィルタリングを表現したものになってましたが、Factorization MachineではUser、Itemの系列データをすべて横持ちの学習データとして保持し、 1行ごとにインタラクションを表現するように表現します。
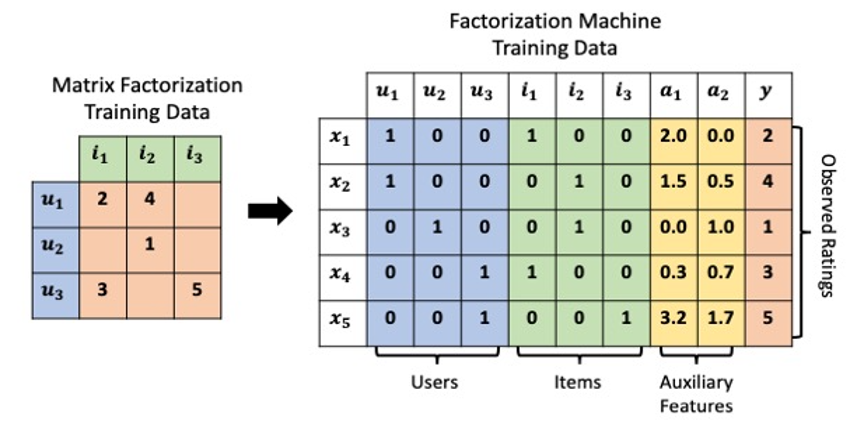
この状況で、推定レイティングを下記の式のように算出します。
ここで、は潜在ベクトルの内積を表します。
これによって、特徴量から作成される2次の特徴量の掛け合わせを暗黙のうちに使用することが可能になります。
これをSGD等を使用してパラメータを推定することで、近似する手法になります。
この辺りが、基本的な推薦アルゴリズムと考えられます。
ニューラルネットワークの推薦システムへの応用の傾向
この段階ですでにお腹いっぱいな感じはしますが、ここまでが背景知識です。 ここまでで基本的な推薦の方法について確認したところで、推薦にNNを適用する事例について確認していきます。
2010年代に一気に発展したニューラルネットワークですが、推薦の世界でも活用されています。 自分の読んだ論文の範囲では、大きく
- Feature Engineeringを効率化するためのNN活用
- 系列データを活用するためのNN活用
の2つが、NNを利用する大きなモチベーションとしてありそうに思えたので、今回はその2種類について見ていきたいと思います。
(もちろん別の目的の研究もあるかとは思いますが、今回はこの辺りがモチベーションになっている流派の論文を読み漁っていたというのもあり、この辺をピックアップしている点にご容赦下さい)
Feature EngineeringとしてのNN
特徴量エンジニアリングは機械学習のモデル作成において非常に重要なポイントで、これは推薦のモデル構築においても同様に非常に重要なポイントです。 特徴量エンジニアリングとして、珍しい特徴量の組み合わせを探す必要が発生したりする場合がありますが、これらにはエンジニアの経験に基づいて手動で特徴量を作成したり、網羅的な探索が必要になり膨大な時間・コストがかかってしまう恐れがあります。
そもそもNNではない中の優れたアルゴリズムだったFactorization Machineは2次の特徴量の掛け合わせを考慮したモデルと考えることができます。
逆に言えば、2次を超える高次の特徴量の組み合わせについてはFactorization Machineでは表現することができません。
一方で、NNを考えると、それは層の数だけ高次の特徴量の掛け合わせを表現できることになります。 複雑な特徴量の組み合わせをNNによって暗黙的に考慮できるとすれば、一般的な推薦の観点で言っても性能が高くなりそうと考えられます。
このように、特徴量エンジニアリングを手動で実施するコストを考えると、自動で適切な特徴量を作成し、それを用いて学習することで特徴量エンジニアリングを簡略化したいというモチベーションがあります。 そこで、推薦システムにNNを使っていく研究が行われています。
Wide & deep
推薦システムにおいてMemorizationとGeneralizationの両立が一つ問題と考え、Wide & Deep では特徴量に関して広いネットワークと深いネットワークを共同で学習させています。
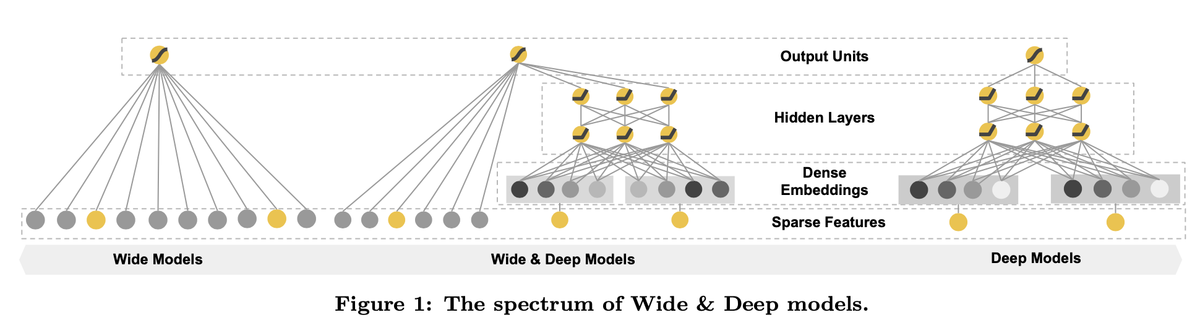
これによって、推薦における大きな疎のベクトルになるものについて、直接的な関係性と複雑な特徴量の組み合わせを暗黙的に使用するように工夫されています。
DeepFM
DeepFMでは、Wide & DeepではWideなNNを使用していた部分について、Factorization Machineを使っています。 また、Wide&DeepではWideネットワークではEmbeddingに変換していませんが、DeepFMではどちらにも密なEmbeddingに変換されてから使用されています。
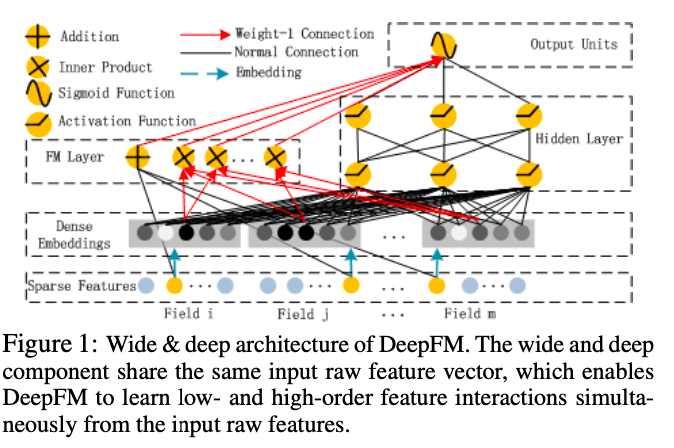
こうすることで低次の特徴量の組み合わせについても効率的に学習し、高い性能を達成しました。
DCN
DCNでは、DeepFMでFactorization Machine, Wide&DeepでWideなネットワークが使用されていたところに、明示的に特徴量の相互作用を計算するCross Networkを使用しました。
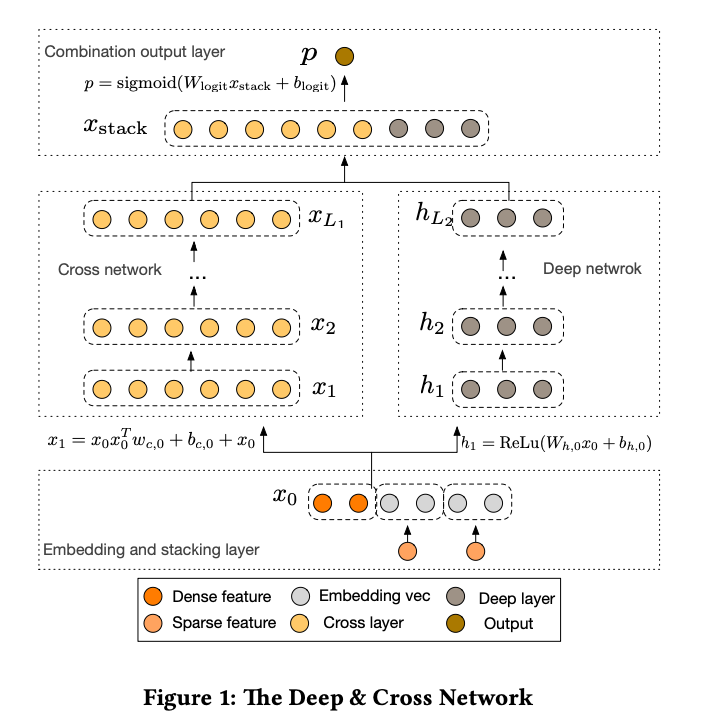
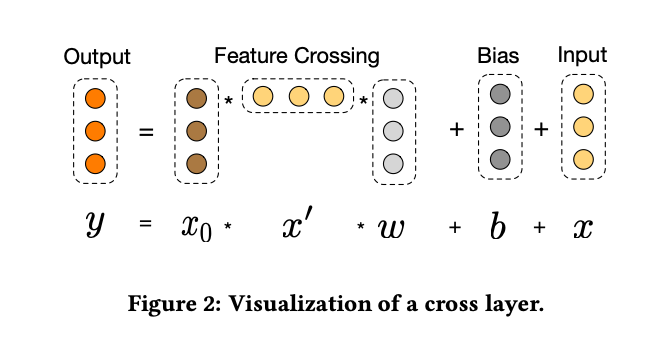
明示的に特徴量クロスを計算するCross Networkを組み込むことで、DCNでは有効な特徴量の掛け合わせを使用するように学習するように設計されています。
AutoInt
先行研究で使用されている全結合型ニューラルネットワークは、乗法的な特徴量相互作用の学習において非効率的であることが示されており、また特徴量のどの組み合わせが意味を持つかに関する説明性についても乏しいものになっていました。 AutoIntでは、Self-Attentionを活用することで効率的に特徴量の相互作用を学習しつつ、説明性に優れたモデルを開発しようとしました。
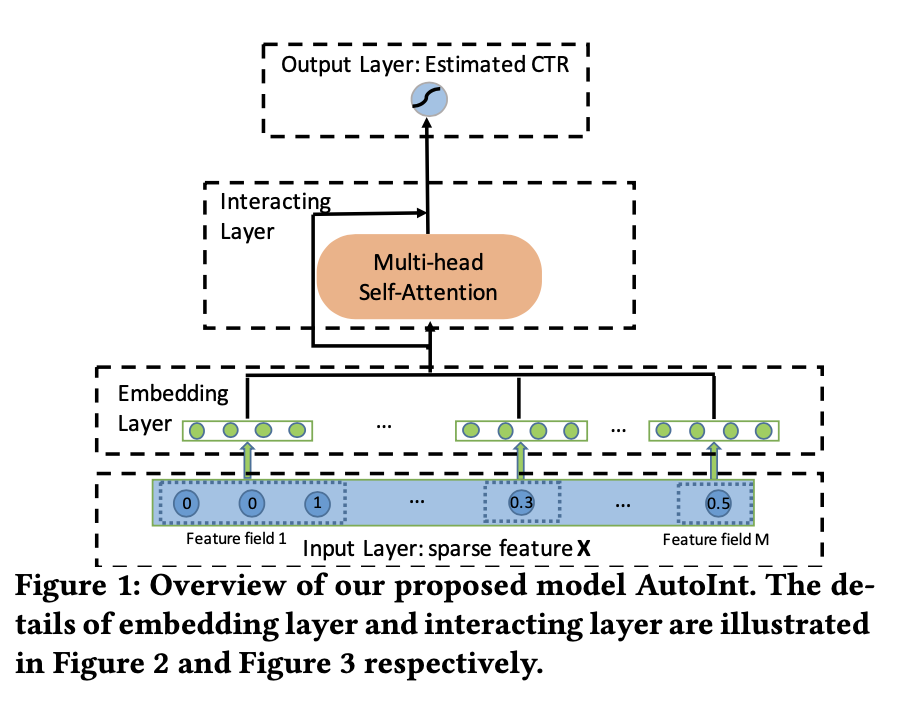
AutoIntでは、sparseになる特徴量をEmbeddingに変換し、そこにAttention層を活用することで効率よく学習できるようにしているといいます。 実際に高い性能を達成できているだけでなく、Attention Mapを可視化することでを特徴量の相互作用を解釈できるようにもなっています。
DCN V2
DCNで適用したCross Networkによる特徴量クロスについて、より効率的に計算できるように改良されたのがDCN V2です。
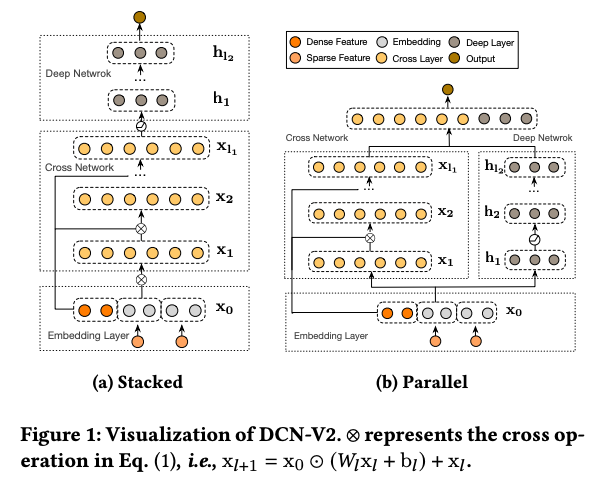
DeepなネットワークとCross Networkを組み合わせ、内部の行列サイズが大きくなることによるモデルサイズが大きくなる問題を行列分解を行うことでパラメータ数を削減し、特徴量の組み合わせを考慮しつつ軽量・高速なモデルになるように改良されています。
系列データとして取り扱うNN
今度は別の切り口でNNを使用することを考えます。 協調フィルタリングベースの推薦やFeature Engineeringを意図したNNによる推薦で使用される特徴量は、基本的にアイテムに関する購入回数やクリック回数などになっています。 そしてこれらの特徴量は、基本的にユーザーの行動の時系列的性質は考慮されていません。
一方で、ユーザーの行動の時系列情報は非常に重要な情報であると考えられており、これを活用するために自然言語処理のアプローチを推薦に適用するという流れで研究が進められてきました。
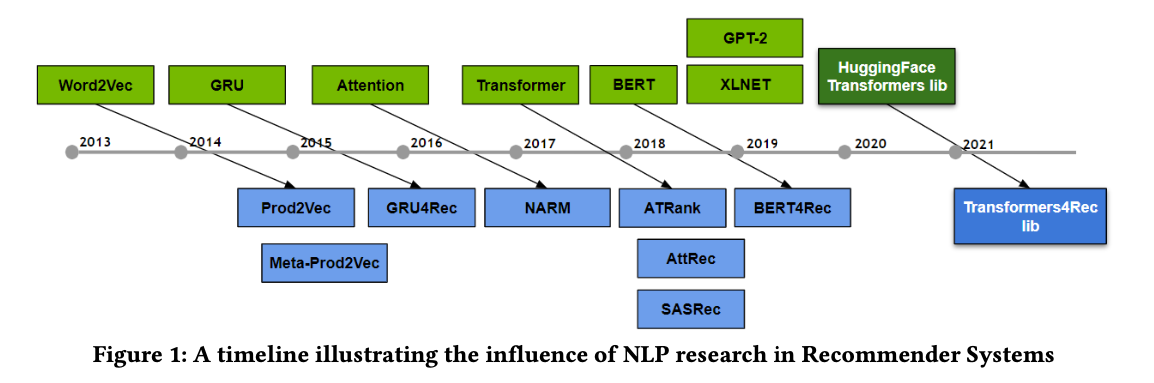
実際、NLPの世界で発表された主要な手法が軒並み推薦に適用する研究が行われていおり、ユーザーの時系列情報をうまく考慮した推薦が行われる様になっています。
prod2vec
prod2vecでは、ユーザーが商品を購入した系列データを使用して、アイテムのEmbeddingを作成します。
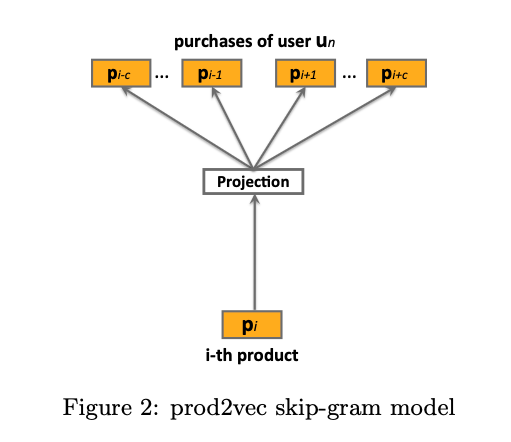
商品は同時に複数購入されることがあり、それぞれについて時間的に前後に購入された商品についてword2vec同様、skip gramでEmbeddingを学習していきます。
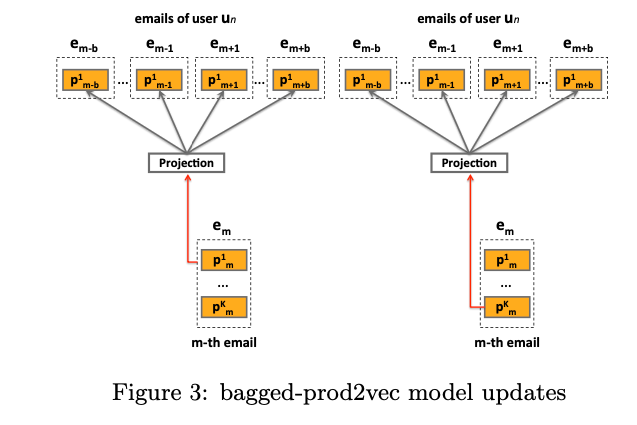
prod2vecでは、このEmbeddingを使用してクラスタリングを行い、ある商品購入後に次にどのクラスタの商品を購入するかを推定し、その後そのクラスタ内でどの商品が購入されるかの確率に基づいて推薦するアイテムを決定していきます。
AttRec
AttRecではTransformerの構造を推薦に適用しています。
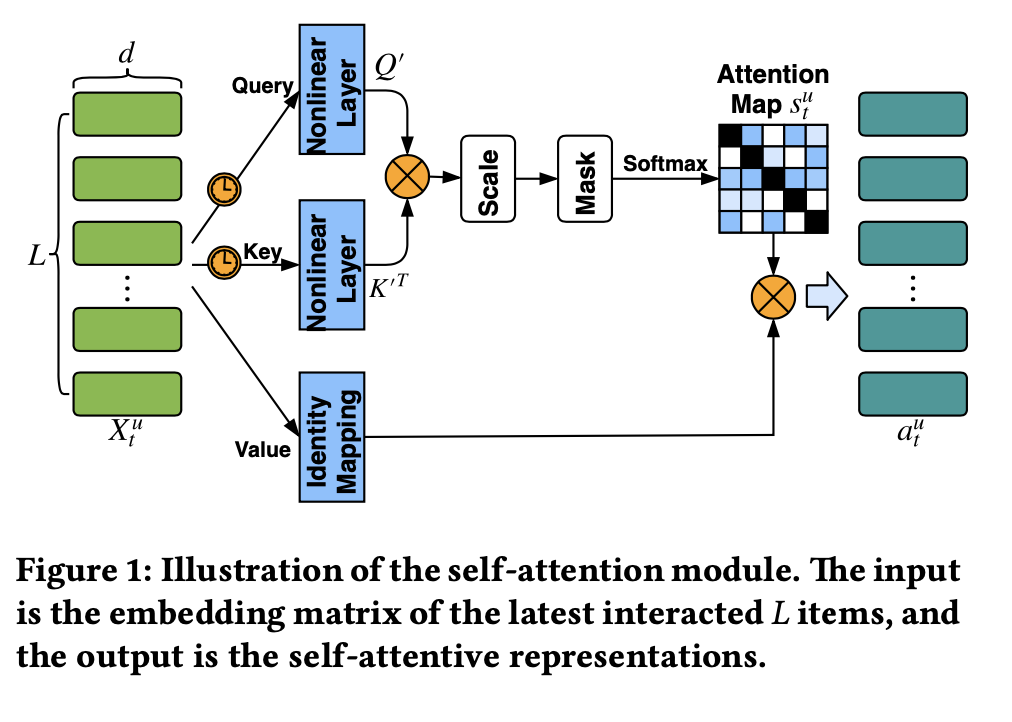
Transformerの構造をそのまま適用しているわけではなく、Query、Key、Valueをすべて同じ値を取り扱う点は、Transformerと若干異なる作りになっています。 また、AttRecではSelf Attentionで短期的なユーザーの嗜好を解釈しつつ、各ユーザーと各アイテムに対して latent factorを割り当てることでユーザーの長期的な嗜好についても考慮するモデルになっています。
BERT4Rec
BERT4Recでは、BERTの構造を推薦システムに適用しています。
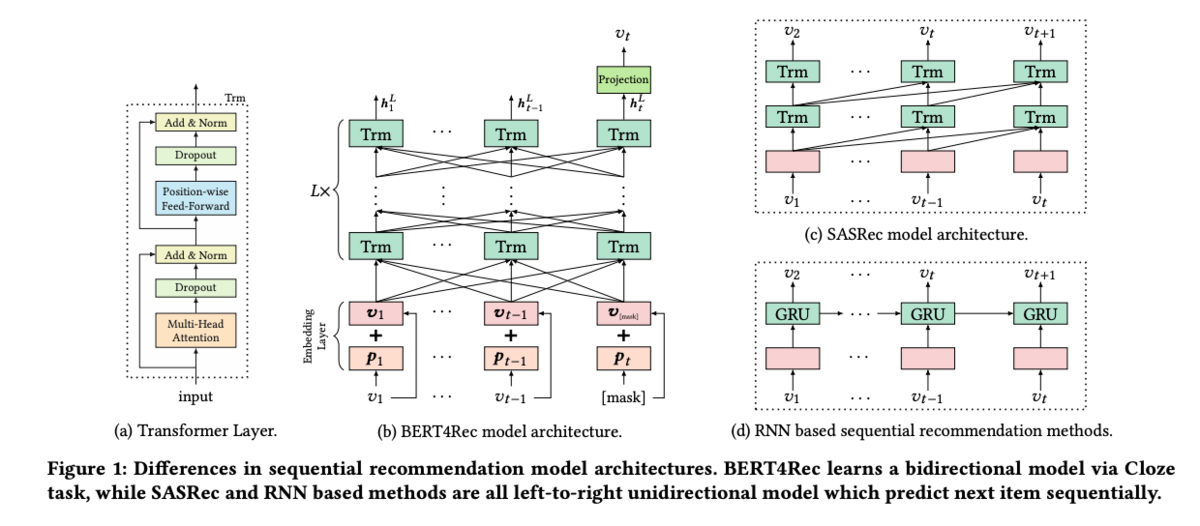
これまでの推薦システムではユーザーのインタラクションについて過去から未来の方向にのみ学習を行っていました。 しかし、何らかの事情でアイテムに関するインタラクションの時系列が逆向きになることも考えられます。 BERT4Recでは、このシーケンスについて双方向に考え、アイテムに対するインタラクションが未来の情報についても使用して、アイテムの学習に使用します。 このとき、当然リークが懸念されますが、そこでmasked language model同様の学習を行い、推論時にはシーケンスの最後の部分を[MASK]にすることでタスクの見方を変えることで対応しています。
Transformers4Rec
その後出てきたTransformers4Recは、これまでのTransformerを推薦に使用したモデルを一般化した感じです。
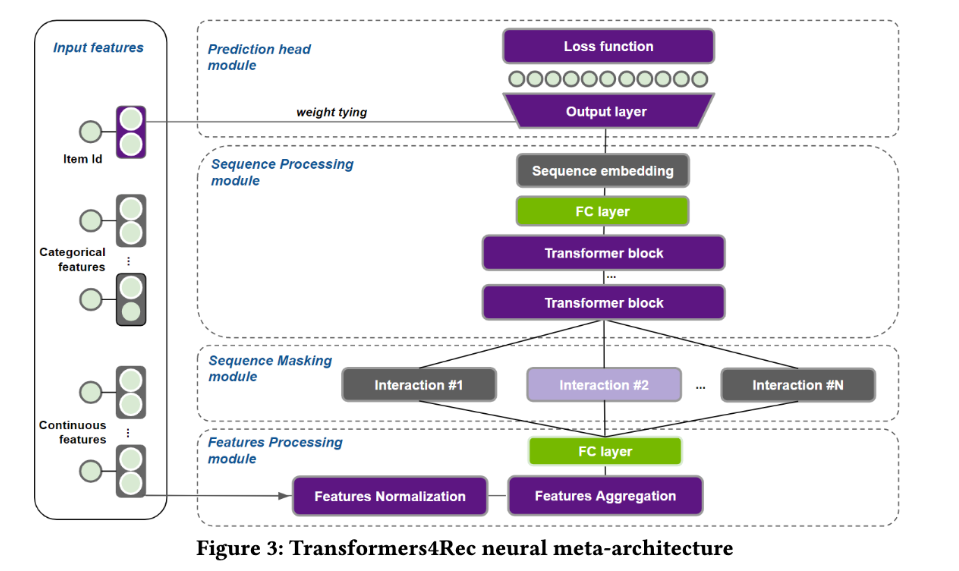
アイテムに関する埋め込みの生成から、Transformer blockの使用等を抽象化し、使用者が簡単に利用できるようにライブラリとして提供しています。 シーケンス情報だけでなく、補助的な情報についても入力できるようになっています。 また、アイテムのEmbeddingは出力層の重みと共有されています。これはパラメータを減らし、学習を効率化する工夫になっているようです。
参考文献
読んだ論文をまとめたやつ
自分の論文メモはこちら。
- Feature Engineering目的関係
- Wide & deep learning for recommender systems · Issue #32 · nogawanogawa/paper_memo · GitHub
- DeepFM: A Factorization-Machine based Neural Network for CTR Prediction · Issue #28 · nogawanogawa/paper_memo · GitHub
- AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks · Issue #27 · nogawanogawa/paper_memo · GitHub
- Deep & Cross Network for Ad Click Predictions · Issue #23 · nogawanogawa/paper_memo · GitHub
- DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems · Issue #20 · nogawanogawa/paper_memo · GitHub
- Sequence考慮関係
- E-commerce in Your Inbox: Product Recommendations at Scale · Issue #38 · nogawanogawa/paper_memo · GitHub
- Next item recommendation with self-attentive metric learning · Issue #37 · nogawanogawa/paper_memo · GitHub
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer · Issue #36 · nogawanogawa/paper_memo · GitHub
- Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation · Issue #35 · nogawanogawa/paper_memo · GitHub
関連書籍
こちらの書籍にも推薦システムのNN活用が紹介されていますので、よろしければこちらもどうぞ。

感想
ということで、個人的にここ何ヶ月かで推薦システムにNNを似たような意図で適用する論文を読んでいたので、自分の頭の整理のために俯瞰していろいろ考えながらまとめてみました。 これについて、また30分くらいの雑談ができそうですね。
ここ数年の歴史的経緯を追っているだけなので特に新しい技法の紹介とかではありませんが、今昔物語的な読み物として楽しんでいただけたら幸いだなと思います。