この記事は (1人で)基礎から学ぶ推薦システム Advent Calendar 2022の9日目の記事です。
前回、(あってるかどうかはわかりませんが)推薦システム開発の大まかな流れを書き出しました。
今回は「推薦精度の評価」をどうするかについて考えていきたいと思います。 文献や組織ごとに考え方が異なるとは思いますが、自分がこれからコードを書いていくにあたっての"精度"の考え方についてまとめる意味でやっていきます。
推薦システムのオフライン評価の難しさ
オフライン評価
前回紹介した流れで推薦システムの開発をしていくと、通常は実装を終えたあとオンラインテストには時間的コストやユーザーの体験を低下させるリスクがあるため、オンラインテストに出す前にオフラインで評価を行います。 推薦のようなユーザーの行動ログデータを使用して評価を行うようなタスクでは、exposure bias・position biasと呼ばれる類の問題が発生する点がしばしば話を複雑にします。
推薦を行うようなサービスでは、ユーザーは表示したアイテムに対してだけしかクリックや購入といった行動を取れません。 一方、その背後には表示されていない大量の未評価のアイテムがあり、これらのアイテムにユーザーがどういった評価をするかは情報がありません。
また、ログ上で購入やクリックされたからと言って、真に良い評価であるとは限りません。 これは、ユーザーは表示されたアイテムの中からアイテムを評価して購買等の行動を取ることになり、見えているアイテム以外を考慮して比較検討を行わないため、見えているアイテムの中での相対評価になりやすいからです。 特に、ランキング等のUIでは通常上位に表示されたほうがアイテムの良し悪しに関わらず良い評価を得られやすくなります。
そのため、ユーザーに対して表示されたかどうか、そしてその上でユーザーがアイテムにどんな評価をしたかを考慮した上で評価する必要があります。
評価値行列がsparse
推薦で扱われる評価値行列は、多くの場合疎行列です。 これが話をややこしくします。
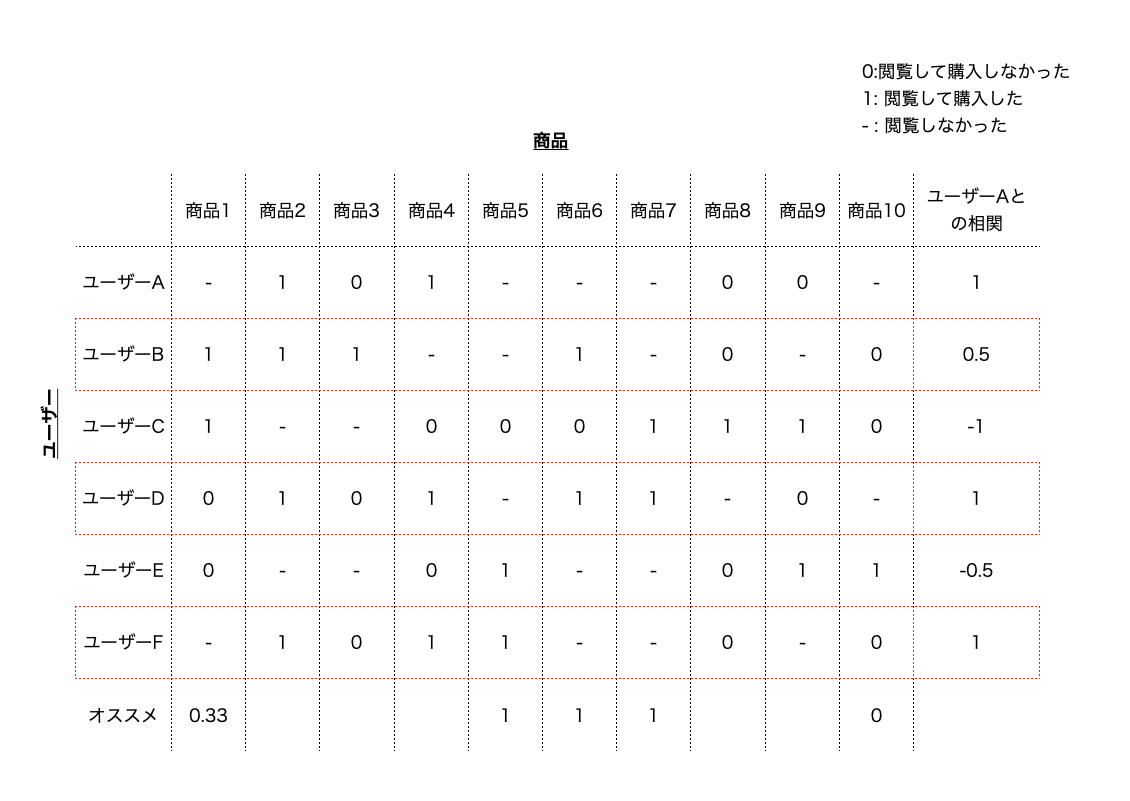
例として、ECで10個の商品をおすすめする状況を考えます。 そして、何らかの推薦アルゴリズムによって10件のアイテムが順位付けされたとします。 この条件下で、先に紹介した未評価のアイテムについて考えます。

上記の図の例では、ユーザーによって評価された記録があるアイテムがそもそも4つしかありません。 それ以外は、今回作った推薦アルゴリズムでは表示されることになりますが、過去は表示されていないためユーザーからの評価がわかりません。 幸運にも評価されていたアイテムに関しては、3/4が実際におすすめしたら購入されるとわかっています。
今度は別のケースを考えます。
上記の図の例では、ユーザーによって評価された記録があるアイテムが1つしかありませんが、確実に購入されることがわかっています。
さて、これら2つの推薦アルゴリズムのどちらのほうが性能が高いでしょうか?
前者の例は評価可能なデータだけで考えれば3/4がpositiveを判定でき、後者の例は評価可能なデータだけで考えれば1/1がpositiveでした。 ただし、実際にはユーザーには評価値が未知のデータがあるので、それらの評価結果次第では十分に優劣が逆転してしまいます。
推薦するアイテムの個数に制限がある
おすすめするアイテムが1個~数個であるケースはもちろん、ランキング形式のようにユーザーが頑張ればすべてのアイテムを見ることができるような状況でも、実態としては途中でユーザーは離脱してすべてを見ることはまず無いので、推薦されるアイテムには限りがあると考えるのが通常です。
このような状況を評価するため、推薦では多くの場合でおすすめ表示順の上位k件(Top@k)だけを使用して評価しています。
例として、ECで10個の商品をおすすめする状況を考えます。 そして、何らかの推薦アルゴリズムによって10件のアイテムが順位付けされたとします。
この状況で推薦システムの振る舞いは、おすすめの度合いに基づいて上位10件をpositiveだと分類するように振る舞います。 先に紹介した未評価データについて考えます。

上記の図の例では、3/4が実際におすすめしたら、購入されるとわかっています。 しかし、推薦されなかったアイテムの中に、「おすすめしていれば購入されたアイテム」が多数入っていますね。 これらは10件しかおすすめできなかったから、仕方なく「購入されない」と分類されてしまっています。
そもそも、どれだけ頑張っても10件しかおすすめできないので、評価対象に入らないアイテムは確実に発生してしまいます。 このように上位k件を使用して評価を行う際には、こうしたやむを得ず溢れてしまったアイテムも考慮する必要があります。
Two Stage Recommendationでの例
推薦システムでよく取られる手法であるtwo stage recommendationでは、
- 1st stage: ユーザーに関連する可能性がある推薦候補を取得
- 2nd stage: 1st stage 取得された推薦候補に対して、関連度の順に並び替え
といった流れで処理が行われます。
例としてこれらのstageで、どのような評価をするかを見ていきます。
※あくまで例なので、サービスの用途によって評価指標はガラッと変わることがあるので悪しからず。
1st stageでの検索精度評価
2nd stageまで終わってからまとめて評価するでも良いですが、ここでは各stage毎に評価をすることを考えます。
1st stage ではおすすめすべきアイテムをどれだけ取得できているかが、精度という観点での1つのポイントになるかと思います。 そのため、ユーザーとアイテムの関連度の有無の類精度が一つの評価指標になるかもしれません。
この分類精度ですが、よく用いられる指標としてprecision, recallなどがあります。 理屈上はf scoreも使えなくはなさそうですが、個人的にあまり論文で使われているのを見ないので今回は割愛します。
ここで、未評価のアイテムの扱いを考えてみます。
precision
precision = 実際に関連度が高かったアイテム数 / 関連度が高いと推定したアイテム数
未評価のアイテムの扱いを考えてみます。 未評価のアイテムは、評価されていないだけで本当は関連度が高いかもしれませんし、逆に関連度が低いかもしれません。 このデータはそもそも評価値を計算することができません。
未評価のデータを除外してprecisionを考えることもできますが、これをやると未評価のデータを大量に推薦候補に入れると精度が曖昧になることが考えられます。
また、関連度が高いと推定したアイテム数が非常に少ない場合(確実に高いと判断したものだけ選択した場合)には、実際には関連しているアイテムが取りこぼされていても精度が高くなってしまうという問題があります。
個人的にはprecisionを使うのであれば、precisionと合わせてp値等も一緒に出してあげて合わせて評価する必要があると考えてます。

今わからないのは、比較したい推薦アルゴリズムの結果、
- positiveと予測したのがa個、実際にpositiveだったのがb個
- positiveと予測したのがc個、実際にpositiveだったのがd個
のような結果が得られたときに、どちらのアルゴリズムが優秀かが知りたいわけです。 それなら、(多少手間ではありますが)両者のアルゴリズムについて検定を行い、より確実に性能が良い方を選択すれば良さそうですね。
recall
recall = 関連度が高いアイテムのうち推定できたアイテム数 / 実際に関連度が高いアイテム数
推薦されなかったアイテムまで考慮するならrecallを使うことができるでしょう。

この場合「判明しているpositiveなアイテムをたくさん推薦できるアルゴリズムのほうが優れている」のように考えて評価することになります。
recallは、推薦候補を多く取れば取るほど精度が上がることになります。 アイテム全体の数に対して大きな割合を推薦できる場合には、モデル精度が過剰に大きく算出されるのでご注意ください。
あくまで個人的な意見ではありますが、precisionを使って評価するよりはrecallを使ったほうがシンプルでわかりやすいなとは思ってます。
2nd stageでのランキング評価
1st stageではどれだけ多くコンバージョンする可能性の高いアイテムを取得できるかがポイントになりそうですが、2nd stageではおすすめ度合いが高いものほど上位に並べることが求められます。
1st stageで評価を行っているのであれば、ここでは1st stageで絞り込まれたアイテムが実際にはどう並べられるかを確認すれば良さそうです。 そのため、2nd stageでは
- nDCG@n
- MRR@n
などで測定するのが一般的に思います。

未評価データの扱いは、ここでもケースバイケースかと思いますが、
- 評価済みのデータの尺度を使用して値をfill
- 一律同じ値をfillする
- ユーザーごとに得られている平均値でfill
- 未評価データを除外
のような対応を取ることで、一応簡単に計算することはできます。
試しに書いてみる
評価の話は後の記事でもつきまとう問題なので、ここでサンプルコードを書いていこうと思います。
ratingの推定誤差: RMSE
いきなりTwo stage recommendationの例ではないですが、RMSEから書いてみます。
データによっては購入の有無などの分類ではなく、商品に関するユーザー評価結果(rating)が与えられていることがあります。 そういった場合は、評価に使用するデータをすべてratingを推論し、それらをすべてRMSEを計算するのが一番シンプルです。
このようなratingの推定誤差を測定する際には、
- ratingがわかっているuser-itemのペアについて推薦モデルによるratingを推論
- すでにわかっているratingとモデルによって推定されたratingのRMSEを計算
の手順で計算すれば良さそうです。
1st stage : Recall
例でも示しましたが、1st stageではおすすめすべきアイテムをどれだけ取得できているかを測定することで評価しようと思います。 状況としては、推論によって、上位k件をおすすめできる状況を考え、上位k件を1, それ以外を0として分類精度を測定することでrecallを算出します。
2nd stage : nDCG
2nd stageでは、並べ替えの結果おすすめしたいアイテムをどれだけ上位に配置できているかを評価するためにndcgを使用して計算したいと思います。 こちらは、分類精度ではないので推定したratingをそのまま入力することで計算します。
サンプル
こんな感じで評価できます。
Off policy evaluation
少しだけ発展的内容にも触れます。
すでに推薦システムを運用しており、それを改善する場合には、ログデータは既存の推薦アルゴリズムを使用した結果が記録されています。 そのため、評価に使用する評価済み・未評価のデータが、そもそも推薦アルゴリズム(policy)によるバイアスがかかっていると考えることができます。

例えば、上の例では1st stageのrecallを考えていますが、もともと稼働していたアルゴリズムではユーザーに表示しているものが全てなので高評価のアイテムがすべて推薦結果に含まれています。 一方、新しい推薦結果Bではそこから変化をつけているので、Recallは低下しています。 しかしよくよく見てみると未評価データが含まれており、未評価データがすべて高評価出会った場合にはBのほうが精度が良さそうに思えます。
このように評価済みデータをなるべく多く取り込んだほうが性能が高くなりやすくなり、従来の推薦アルゴリズムの結果に近い結果になるアルゴリズムであるほうが優れていると判断しやすくなってしまいます。 このような問題に対応するためにオフ方策評価(Off policy evaluation, OPE)という分野があるので、興味がある方は勉強してみることをおすすめします。
参考文献
このあたりの理論に関してより詳しく知りたい方はOff policy evaluationという分野が参考になります。 下記の書籍が非常に参考になります。
