
2/18までKaggleで行われていたRainforest Connection Species Audio Detectionに参加してました。 それに取り組む中で勉強した事を備忘として記録していきたいと思います。
これは何?
音声系のコンペに取り組むのが初めてで、せっかくなので勉強した事を記録に残しておくものです。
どんなコンペ?
In this competition, you’ll automate the detection of bird and frog species in tropical soundscape recordings. You'll create your models with limited, acoustically complex training data. Rich in more than bird and frog noises, expect to hear an insect or two, which your model will need to filter out. Rainforest Connection Species Audio Detection | Kaggle
DeepLによる翻訳はこんな感じです。
このコンペティションでは、熱帯のサウンドスケープ録音における鳥やカエルの種の検出を自動化します。限られた音響的に複雑なトレーニングデータでモデルを作成します。鳥やカエルの鳴き声だけではなく、虫の声が1~2匹聞こえてくることが予想されますが、これはモデルがフィルタリングして除去する必要があります。
ということで、鳥やカエルの鳴き声の音声からそこに存在する生物の種類を特定するコンペです。
イメージはこんな感じ。
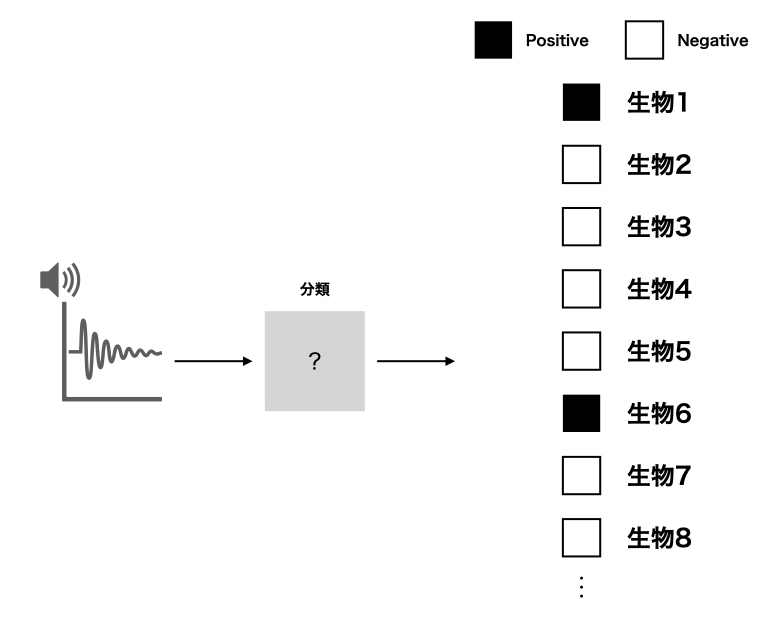
評価指標はLRAPというやつでした。
詳しくはこちらをご参照ください。
コンペの主題(個人的見解)
大体のコンペには、勝負の分かれ目になるようなポイントがあったりします。 ディスカッションなどを見る限り、このコンペの厄介な点はデータのラベルが弱ラベルな点でした。
通常のラベルは以下のようにはっきりと正解・不正解のラベルが確認できるようになっています。
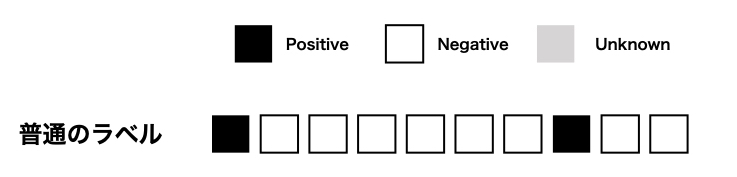
一方このコンペで使用されていた弱ラベルがどういうことかというと、こんな感じです。

部分的に1 or 0がわかるもののそれ以外は0なのか1なのかわからない、そんなラベルになっています。 そのため、与えられたラベル意外にも正例が含まれてい可能性があるという点がポイントになります。
ほーん。で、何位だったの?
publicで147位、privateで140位でした。銅メダルが114位以上なので、26位足りませんでした。

はい、この記事書いてる人間は、メダル圏にカスリもせず惨敗しています。 ということで、普通に負けたので反省としてこの記事を書いているわけです。
勉強したこと
ここからはコンペに取り組む上で勉強した内容についての備忘録です。 ノートブックとかディスカッションを読む上で、前提になっているようなものを勉強したつもりです。
音声関係
今回のコンペは音声データが対象だったので、音声固有の考え方について勉強していました。 なかなか知らないことが多かったのでメモしていきます。
Short Time Fourier Transform: STFT
STFTの話をする前に、フーリエ変換についてかんたんに紹介します。 音声信号を始めとする波形データでは「重ね合わせ」という現象が起きています。
これにより、我々が観測している音声などは様々な周波数の波が重なり合って形成されたものであると考えることができます。 これを逆に考えると、我々が観測している音声データは、特定の周波数の波の成分に分解して考えることができるということになります。 そして、この「特定の周波数成分に分解」するのがフーリエ変換です。
通常、フーリエ変換は観測されたデータの時間幅いっぱいについて考えます。 これは、対象にしている波形データが定常(傾向が変動しない、同じパターンを繰り返す)であることを前提にしています。 これでは突発的に発生する音声について正しく周波数変換することができません。 そこで、波形データを短い時間区間で区切ることで、「その短い時間区間の中では定常である」と考え、その中で周波数変換を行うことがSTFTというわけです。
HzとMel
音声を始めとする波形に関して、上で書いたように異なる周波数の波が重なったものを我々は観測しています。 この「周波数」は、一般的にはHz(ヘルツ)の単位が使用されることが普通かと思います。
しかし、Hzはあまりに客観的な指標であり、人間の感覚からは乖離することがあります。 実際、人間は高周波数(高い音)に関しては、精度良く聞き分けることができず、高周波数領域では周波数の増加と人間の感じ方はリンクしないようです。
そこで、人間の感覚に合わせた周波数の指標としてMel(メル)があります。
メル尺度(メルしゃくど、英語: mel scale)は、音高の知覚的尺度である。メル尺度の差が同じであれば、人間が感じる音高の差が同じになることを意図している。 メル尺度 - Wikipedia
Melを使用することで、より人間の感覚にあった尺度で音声波形を考えることができるようになります。
Spectrogram
音声などの波形データでは、上で書いたように周波数分解することが一つのポイントになりそうです。 ただ、その周波数領域をどのように表現するかはまた別の問題になってきます。
Spectrogram(スペクトログラム)は、横軸に時間を、縦軸に周波数を取った二次元格子に対して、各座標に対してその時刻・周波数の成分の大きさを色で表現した表現形式です。
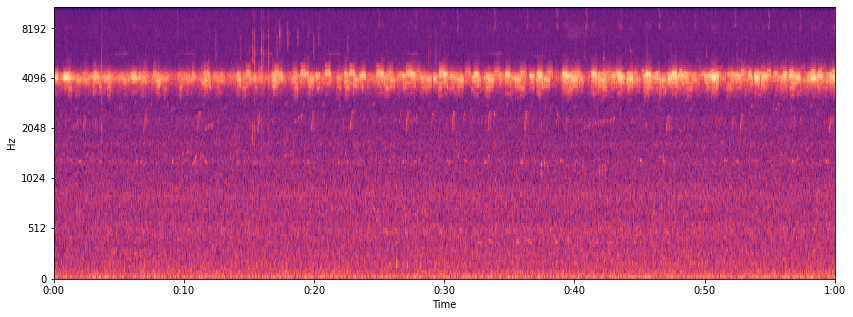
これによって、どの時間にどの周波数成分が強く含まれていたかを俯瞰して確認することができます。
コードとしてはこんな感じで画像を作れたりします。
コード
def spectrogram(filepath:str, y_axis='hz'): trx, trsr = librosa.load(filepath) TRX = librosa.stft(trx) TRXdb = librosa.amplitude_to_db(abs(TRX)) plt.figure(figsize=(14, 5)) librosa.display.specshow(TRXdb, sr=trsr, x_axis='time', y_axis=y_axis) plt.colorbar() return
Cepstral
Cepstralは下記のような説明がされています。
ケプストラム(英: Cepstrum)とは、音のスペクトルを信号と見なしてフーリエ変換 (FT) した結果である。"spectrum" の最初の4文字をひっくり返した造語。ケプストラムには、複素数版と実数版がある。 ケプストラム - Wikipedia
パワースペクトルを時間信号だとみなして、更にフーリエ変換するものです。
Mel Spectrogram
通常のスペクトログラムでは、縦軸の周波数にはHzが使用されるかと思いますが、Mel Spectrogramでは縦軸にMelが使用されているわけです。 これによって、より人間の感覚に近い状態でスペクトログラムを表現することになります。
コードとしてはこんな感じで画像を作れたりします。
コード
def melspectrogram(filepath:str): trx, trsr = librosa.load(filepath) melspec = librosa.feature.melspectrogram(trx, sr=trsr) plt.figure(figsize=(14, 5)) librosa.display.specshow(librosa.power_to_db(melspec, ref=np.max), y_axis='mel', x_axis='time') return
機械学習関連
公開されているノートブックやディスカッションを見る限り、Spectrogramを画像としてみなし、それをCNN系を使って分類器を作成するアプローチが多い感じがしました。 あまり画像系に明るくなかったので、名前だけは知っていたResNetを勉強してました。
ResNet
層の大きいCNNを考えたとき、その学習がうまく進むように、層の入力を参照した残差関数を学習するようにしたものがResNetです。 こちらの記事は非常にわかりやすかったです。
問題は、使った事なかったんですよね。 ということで、今回いい機会だったので、使い方も一緒に勉強してみました。*1
EfficientNet
最近では、EfficientNetなるものもkaggleではよく使用されているようで、そちらも使ったことがなかったんですが勉強していました。*2
Sound Event Detection (SED)
おそらく、このコンペにおける一つのキーワードであるSED(Sound Event Detection)についても勉強してみました。
音声認識のタスクの一つで、今回のコンペもSEDに読み替えることができます。
PANNs
SEDを含む、様々な音声関係のタスクにおいて、優れた精度を達成しているモデルにPANNsというものがあります。
実際にこちらを適用する事になったので、こちらについても勉強しました。
PANNsの論文で提案されているモデルアーキテクチャは下記のようなものとなっています。
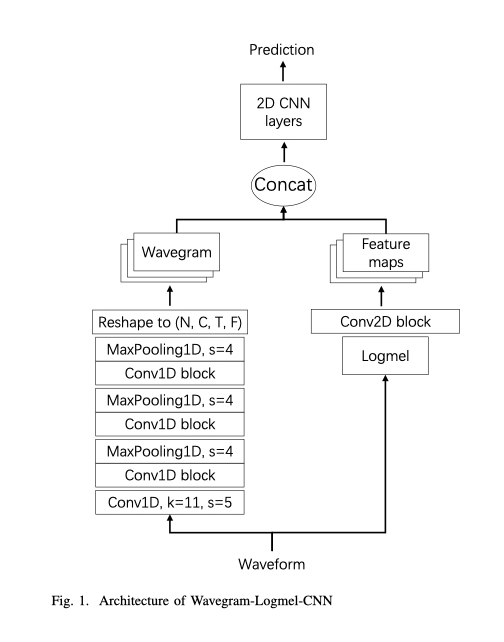
データが下から上方向に流れるようになっています。 大まかなステップは二段階で、
- 音声波形 からFeature maps とWavegramを作る
- それらを合わせた(concat)ものを2D CNN によって最終的な種別の存在確率を算出する
となっているようです。
Mixup
公開されているnotebookを見ると、しょっちゅうMixupという文言が書いてあります。 これは、data augumentation (データ拡張)の手法の1つで、複数のラベル/データ双方を線形補完します。 参考にさせていたいたのはこちら。
私は全く使用しませんでしたが、他人のnotebookを読む上で必要な知識なので勉強したりしてました。
ライブラリ関連
音声データを取り扱うということで、普段は触らないライブラリも使用していく必要があります。 そういった点でも、新しいツールも勉強してました。
Librosa
音声信号を取り扱うときに便利なライブラリです。
今回は特にスペクトログラムを作成する際なんかは、こちらのライブラリでちゃちゃっと作成することができたので、いろんな方が使用していた印象でした。
torchlibrosa
こちらにも書いてありますが、Librosaの機能をPytorchを使って実装したものです。 そのため、Librosaより高速に処理することが可能となります。
実際にとった戦略
ここからが実際にやったことになります。 public LBの変遷はこんな感じでした。
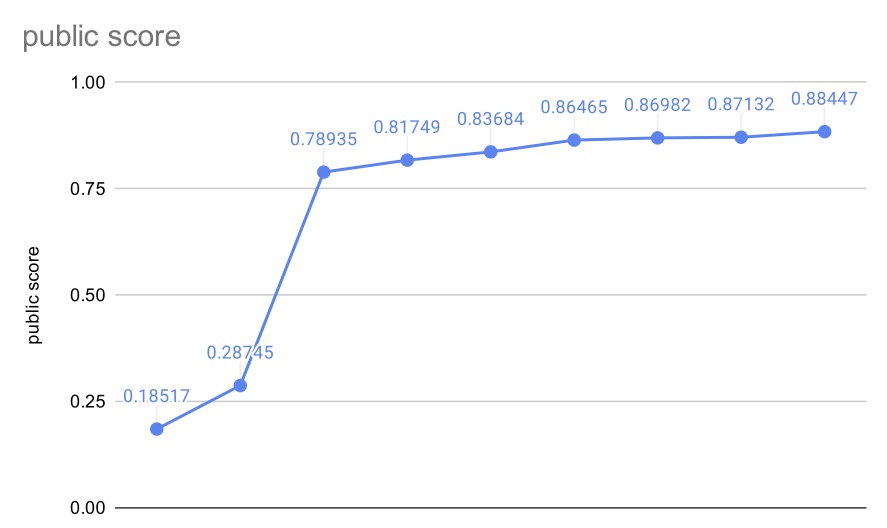
とりあえずResNet34でやる
この領域にあまり土地勘がなかったので、公開NotebookやDiscussionをいくつか読んでみてMelSpectrogramを使えば画像に変換できることを知り、ResNetでベースラインを実装しているケースが多いと感じたので、一旦そこを目指して実装してました。
この辺を参考にしながら、自分でいじれるようにベースラインを作っていました。
全然スコアは出ませんでしたが、ここはなんとなく動けばいいかと思ってやってたので気にせずやってました。
SEDの導入
このへんで、ディスカッションから情報を拾うようになり、こちらを見かけました。
何やらSound Event Detection なるものが有効ということが書かれていたので、とりあえず試してみることにしました。 いろいろDiscussionを読んでいって読み取れたキーワードとしてはPANNsというモデルが非常に有効そうだというところまでたどり着きました。
ディスカッションの内容を踏まえて、修正を加えて実装しました。
Data Augmentationを全部撤廃
私の実装での話になりますが、Data Augmentationが全く効いてないどころか、悪い方向に作用しているように感じたので、一旦全部排除して実装し直しました。 スコアが上昇する兆候が見えたので、EfficientNet b0〜b7ですべてやり直しました。これでシングルモデルでpublic LB で0.864まで行ってました。
SED(EfficientNet)のアンサンブル
SEDを使ったモデル単体で、だいたいスコアがLBで0.864(efficientnet b7)が観測できた最高値で、ちょっとこれではメダル圏まで一歩届かない感じでした。
このへんで、複数のモデルを組み合わせてスコアを向上させるアンサンブルに手を出すことにしました。
はじめはとにかく平均を出していました。 これだけでもちょっと向上して、public LB で0.869くらい出てました。
このへんでOptunaで加重平均のパラメータを決定することを考えて、やってみると最終的にpublic LB で0.871くらい出てました。
ResNet、WaveNetとのアンサンブル
上のアンサンブルをやりきった段階で終了の4日前だったので、あとは大したことはできないなと判断し、公開ノートブックでスコアの良いものを参考にすることにしました。
私の提出よりスコアの良いものがいくつかあり、その中でいくつか試した結果ResNet+WaveNetがアンサンブルしたときのスコアが最も良くなったので、それを最終提出とし、その結果140位で終わってしまったというわけです。 本当に情けない…
上位解法の復習
ここまでが自分でやったことです。 「じゃあどうやったら勝てたのか?」という点が次に気になります。 ということで、上位解法をざっくり確認していきたいと思います。
1位
一位解法の特徴はこんな感じです。
- 数種類のCNNモデルのアンサンブル
- 音声のメルスペクトログラムを使用
- 提供されたアノテーションのみを考慮するために、損失関数の一部としてマスキングする
- Hard labelとWeak labelの組み合わせ
- pseudo labelingの結果を重み1ではなく0.5として使用する
Hard label と Weak label
この解法の特徴は、Hard labelで学習したモデルとWeak labelで学習したモデルを組み合わせる点でしょうか。 先にも書いたようにこのデータセットはWeakなので、指定されていないところに対象の生物の鳴き声が発生している可能性があります。 そのため、TPのラベルが与えられている区間だけを切り取って、その部分だけを使用して学習するのがHard Labelのようです。 こうすることによって、正例・負例がわからないものを排除して、わかるところだけに着目して学習を行っているようです。
ただし、これだと与えられていないラベルの鳴き声について考慮されていないので、このモデルを使ってPseudo labelingするようです。 一段目でHard label学習したモデルを使って疑似ラベルを作成し、手動で付与したラベルをもとのラベルに追加して、再度学習を行ったようです。 これをWeak labelの学習と呼んでいるようです。 なお、二段目の学習にはnoisy studentモデルを使用したようです。
最後に、これら2つを組み合わせた複数のモデルをblendingします。 blendingの方法も多くを組み合わせていて、Max Blend(複数出力のうち最大値を採用)やMean Blend(出力のを平均)を使用し、それらをスケールをべき乗や線形といろいろ変換して、最後に平均を取るようです。 blending と一口に言っても色々あるんですね。
その他、特定の種のラベルに対して手動でラベル付けするなどすると、スコアが大きく上昇するそうです。
2位
2位解法も、ベースになるのはログメルスペクトログラムに対する24クラスの画像分類となっているようです。 使用したモデルはEfficientNetとRexnetとしたようです。
こちらも、与えられたTPのラベルに基づいた短形に区切って一段目のモデルを作成し、それを使用してpseudo labelingを行っています。 ただし、二位解法ではpseudo labelingは複数回繰り返すことでスコアが上昇したそうです。
3位
3位解法では8種類のモデルの平均によるブレンディングとなっているようです。 さらにモデルの予測後に、後処理として特定のラベルだけを1.5倍にすることで、データセットに存在していた分布の偏りを補正しているようでした。
こちらの解法では、非常に多くのハンドラベルを使用しているようです。 そのせいなのか、pseudo labelingは思ったより機能しなかったようです。 こちらはpseudo labelingで0.8以上のものだけを採用するという、厳し目のpseudo labelingにしているようです。
4位
4位の方は、上3チームと違いSEDで実装したようです。 構成としては大きく3段階になっており、
- EfficientNetB1-B3で、song typeも考慮して26クラスで分類
- 1段目のモデルを使用してpseudo labeling後、二段階目の分類
- SED
- 通常の画像分類(EfficientNet, ResNetなど)
- アンサンブル
上位解法でSEDが使われている点が特徴的で、pseudo labeling後にはSED+他の画像分類手法を組み合わせているのが特徴的かと思います。
5位
5位のチームは日本の方で、こちらに日本語でまとめられています。詳しくは下記をご確認くださいませ。
上位解法に目を通した所感
実装の中まで見てないので細かいところは言えませんが、メルスペクトログラムに変換して、その画像をどう料理するかというところまでは全員同じかと思います。 その料理の仕方が、シンプルなImage Classiferで解いたのが上位3チームで、4位のチームがSEDで解いた、といった具合です。 そのため、今回に限っては、若干Image classiferのほうが筋が良かったのかな、という印象です。 ただ、金メダルを取るのであってもSEDで取れているチームがあるので、どちらで戦ってもいい勝負まではいけたのではないでしょうか。
おそらく、上位に入っていた人のポイントとしては、こんな感じだと思います。
- pseudo labelingをしてweak labelを考慮
- masked loss
- train/testの分布の違いに着目して、特定の種の存在確率を定数倍
あとは、アンサンブルのテクニックだったり、ハンドラベリングを追加してたりしますが、だいたい同じような方針になっていたかと思います。この辺を思いついた人が上位に入っていて、私は思いつかなかったのでメダル取れなかったんでしょうね。
参考文献
下記の記事を参考にさせていただきました。

- 作者:戸上 真人
- 発売日: 2020/08/24
- メディア: Kindle版
work-in-progress.hatenablog.com
work-in-progress.hatenablog.com
http://abcpedia.acoustics.jp/bs13_q4.pdf
感想・反省
やってみた率直な感想としては、非常に難しく同時に非常に面白い題材だなと感じました。 参加した方は本当にお疲れさまでした。 個人的にはこうして色々勉強になったので、また似た機会があったら活かしていきたいと思いました。
自分に関して言えば、本腰入れて取り組み始めたのが2/4だったので、大体2週間くらいコンペやってました。 これだけ時間があったのに、自分のやったことといえばディスカッション読んでそれをそのとおり実装して、公開ノートブックを読んでそれをチョロっといじっただけです。
上位解法読んでると自分がやったことがスタートラインくらいにしかなってなくて本当に恥ずかしくなりますし、この記事公開するのも本当に恥ずかしいんですが、振り返りは大事なので恥を承知で書くことにしました。 これだけ何もやってない解法でも、順位とスコア的にはもうちょっとやればメダル圏ってくらいだったので、次はもうちょっと頭使って頑張りたいと思います。
今年はこんな感じで、勉強の一環でKaggleに取り組めたらいいなーと思ってます。