
ちょっと画像検索が必要になることがあり、良い機会なので復習しようということになりました。 過去にはこんなのをやってみたりしました。
今回は改めて、主にこちらの資料を参考に画像検索に関して復習してみました。
今回はこちらを参考にアプリを作ってみたのでそのメモです。
画像検索
通常の全文検索では自然文について検索を考えますが、画像検索では検索対象(アイテム)が画像になっており、メタデータを除けばアイテムに自然文が存在しません。 そのような条件下で、ユーザーの情報要求を満たすアイテムのリストを取得することをこの記事では画像検索と定義して話を進めます。
画像検索の方法を整理すると、だいたい下記のような分類に落ち着くかと思います。

これらについて、下記でもう少し詳細に見ていきたいと思います。
TBIRとCBIR
クエリの結果が画像であれば画像検索と呼ぶようで、その実現方法にもいくつかあります。
画像検索は大きくTBIRと(Text Base Information Retrieval)とCBIR(Content Based Information Retrieval)の2つに大別できるようです。
TBIRは、画像にメタデータとして紐付けされたテキストに対してクエリを発行する方法です。 この場合、入力はテキスト、もしくはメタデータ付きの画像になることが想定されます。 (Image recognitionでその場でメタデータを推定することもできなくはなさそうですが、今回はそれは置いておきます)
一方、CBIRは画像の情報を使用して、類似する画像を検索する方法です。 そのため、CBIRでは入力は必ず画像になります。
TBIRはメタデータさえ取り出せてしまえば、全文検索エンジン等を使用することで比較的簡単に実現することができます。 今回はそれよりも厄介なCBIRを実現することを考えていきます。
CBIRの実現方法
CBIRを実現するには、入力画像にどの程度似ているかを評価することでランキングを生成します。 概念的にはこんなフローになるかと思います。
- 特徴量算出
- 類似度算出
- 類似度に基づいてソート
この前提を置いたとき、
- 特徴量
- 類似度の評価方式
によって、ランキングの特性が決まることがわかります
画像検索として使用する特徴量
まずは画像検索で用いられる主な特徴量について見ていきたいと思います。
RGB
画像が持つRGB値をそのまま使用して類似度を評価する方法が最もシンプルな方法です。 画像中の色がどの程度変化しているかをピクセル単位で算出し、変化量が少ないものほど似ている画像を判断することができます。
Histgram
個別のRGB値ではなく、画像全体から得られるRGBのヒストグラムも類似度を判断するのに役立ちます。 この場合、画像中の物体が多少移動していたとしても、ヒストグラムには影響を与えないようになります。
Average Hash
RGB値をそのまま使うと、画像の拡大縮小などの処理をもろに影響を受けてしまいます。 Average Hashでは、画像のRGB値を固定長のハッシュ値に変換することで拡大縮小の影響を軽減して検索を行うことができます。
Perceptual Hash
Average Hashと同様にRGB値からハッシュ値を算出する方法で、算出の方法が離散コサイン変換を使用して周波数成分からハッシュ値を生成する方法です。
SIFT
画像全体ではなく、画像中の局所的な小領域について表現したものを局所特徴と呼び、その代表例とも言えるのがSIFTです。
SIFTは
- 局所領域内の各画素を強度と傾き角度で表現される輝度勾配画像に変換
- キーポイントを中心にしてガウス分布で重み付け
- 空間x, yと方向θの3つで表現される空間に対するヒストグラムで表現
といった手順で計算されます。 一般的なSIFTでは、ヒストグラムは空間方向に4×4、方向θが8次元として、合計128個のbinで表現されることが多く、このヒストグラムを正規化したものが最終的なSIFT記述子として計算されます。 要するに、普通は最終的に長さ128のベクトルが特徴量として算出されるということです。
SURF
歴史的に、SIFTの後にSIFTよりも高速に計算ができるように考案された特徴点の表現方法がSURFです。 基本的にはSIFTと似たようなことをするのですが、輝度勾配を求めるときにSIFTではガウシアン勾配を使用して算出していたものをSURFではハールウェーブレットを使用することで高速化しています。
また、最近ではSIFTやSURFの他にAKAZEなども使用される気がします。AKAZEについては作者のホームページを御覧ください。
この辺の局所記述子について詳しく知りたい方は、こちらの書籍に詳しく書いてありますので一読することをおすすめします。
NN Embedding
上記の特徴量とは異なり、ニューラルネットワークのEmbeddingを使用した検索の方法です。
考え方としては、画像分類として学習されたNNのモデルにおいて、同一のラベルがついた画像に対して、最終層に入力されるEmbeddingは似たものになるであろうという予想から、これらのEmbeddingが近いものは類似画像であろうと考える方法です。
類似度の評価方式
次に類似度の評価方式について確認していきます。
Bag of keypoints
自然言語の文脈で、よくBag of wordsがコーパスの特徴量として利用されます。 その拡張である、Bag of keypointsは単語でなく特徴量の集合で表現されます。 特徴点の表現がどの程度合致しているかによって、画像の類似性を評価することができます。
Earth Mover's Distance
2つの分布の間の距離を考える際にはEarth Mover's Distanceが用いられたりします。 これは2つの特徴量の分布が与えられたときに、片方の分布をもう片方の分布に移動させるときの仕事量を距離として考えることで算出されるようです。
SVM
特徴量が算出されているため、2つの画像から得られた特徴量から類似性を判定するモデルを作成することで類似性をはんていすることは可能です。
ただ、この方法だと検索対象全てに対して一度推論を行う必要があるため、検索対象の規模が大きい時には速度的に問題になるかもしれません。
ハミング距離
wikipediaによればこのような定義になっています。
情報理論において、ハミング距離(ハミングきょり、英: Hamming distance)とは、等しい文字数を持つ二つの文字列の中で、対応する位置にある異なった文字の個数である。別の言い方をすれば、ハミング距離は、ある文字列を別の文字列に変形する際に必要な置換回数を計測したものである。 ハミング距離 - Wikipedia
ハッシュ値等の特徴量を採用する場合には、ハミング距離を用いることで2つの特徴量の間の距離を算出することで類似度を算出することができます。
コサイン類似度
コサイン類似度は、ベクトル空間において2つのベクトルがなす角のことです。
NN Embeddingを使用する際には、特徴量がベクトルとして得られるので、ベクトル間の距離をコサイン類似度とみなすことで、画像の類似性を評価することができます。
要するに
要するに、特徴量とそれに即した類似度の評価方式によって入力画像と検索対象の画像の類似度を算出して、その結果に基づいてランキングを作成すればCBIRは実現できるってことです。あとはその組み合わせ方によって特性が変わるわけです。
上に紹介した意外にも、ハッシュテーブルを使用した検索方法などもあるようで、こちらの書籍をぱっと見た限りでも色々実現方法はありそうでした。
作ってみる
概要が何となくわかったところで本題です。 実際にアプリを作っていきます。
特徴量とか類似度の算出だとか、ムズカシイことをつらつら書いてきましたが、実装するときは先人の作ったライブラリを使うだけなので、実は実装はそれほど大変ではなかったりします。
(それが良いんだか悪いんだかはよくわかりませんが)
全体構成はこんな感じになっています。

対象画像
今回は、The Oxford-IIIT Pet Datasetを使います。
特徴として、
- 37種類のペットの画像
- 画像サイズはまちまち
のようになっています。 画像の種類もたくさんあるので、色々いじるには丁度いいかもしれません。
画面まわり
みんな大好きstreamlitを使います。
正直画面作るのめんどくさかったです、すいません…
検索周り
基本的なアプリの機能はstreamlitで事足りそうです。 検索周りでは、実際の画像検索を行うために必要な処理について考えます。 具体的には大まかに、
- 特徴量作成
- 近傍探索
- 該当インデックスのアイテムを応答
という流れになります。
特徴量の種類によって検索インデックスとして使うツールを変更することを考えます。
基本的にはElasticsearchで事足りると思いますが、場合によっては近傍探索ライブラリも使えます。 この辺の技術選定についてはお好み・条件次第でやったら良いと思います。(すっとぼけ)
pHash - ハミング距離
pHashとハミング距離を組み合わせて類似画像を検索することを考えます。 pHashによって、算出された画像のハッシュ値の間のハミング距離によって類似度を算出します。
pHashの算出はこんな感じです。
import imagehash import cv2 from PIL import Image def get_hash(image_path) : try: hash = imagehash.average_hash(Image.open(image_path)) except cv2.error: ret = 100000 return hash
次に算出したハッシュ値を使って、ハミング距離を使用して検索することを考えます。 クエリのjsonはこんな感じになります。
{ "query": { "fuzzy": { "filename": { "value": hash, "fuzziness": "AUTO", "max_expansions": 50, "prefix_length": 0, "transpositions": true, "rewrite": "constant_score" } } } }
今回はElasticsearchのFuzzyクエリを使用して、ハミング距離が一定以内の画像にフィルタリングし、その後フィルタリングされた画像に対してハミング距離に基づいてソートするようにしたいと思います。 ElasticsearchのFuzzyクエリだと、フィルタリングはできてもスコアリングはできないので、ランキング作成はElasticsearchの外側でやる感じになります。
AKAZE - histgram intersection
AKAZEとhistgram intersectionを組み合わせることによって類似画像を検索することを考えます。
AKAZEではSIFT同様、特徴点・局所特徴量を算出します。 局所特徴量は128次元のベクトルになっており、それが検出された特徴点の数だけ算出されます。
検索画像の集合で得られる局所特徴量を使用して、クラスタリングによってクラス分類器を作成し、このクラスに対するヒストグラムを画像ごとに作成します。

ただ、局所特徴量からクラスに振り分ける際にクラス数を決める必要があるのですが、そこはx-meansでいい感じに設定しました。 残念ながらG-meansは1日では計算が終わらなかったので、今回はX-meansの結果を信用することにしたいと思います。
上のコードによると、クラス数は20が適切のようなので20クラスで分類することにします。
実装としては、特徴量の算出はこんな感じになっています。
def get_akaze_feature(image_path) : akaze = cv2.AKAZE_create() img = cv2.imread(image_path) kp, des = akaze.detectAndCompute(img, None) return des
これをk-meansで教師なし分類します。
model = KMeans(n_clusters=20, init='k-means++', random_state=0).fit(features)
これによって、局所特徴量が得られた際に、それが属するクラスへと変換することが出来るようになります。 これにより各画像はそれぞれ局所特徴量のクラスに関するヒストグラムで表現することができます。
ここまでが事前準備で、実際の検索時に対しても同様に、クエリの画像の特徴量算出、特徴量からクラスのヒストグラムの算出を行います。 更に、検索対象となる画像のヒストグラムをすべて取得し、それらについてhistgram intersectionを算出することで、類似度のランキングを作成することができます。
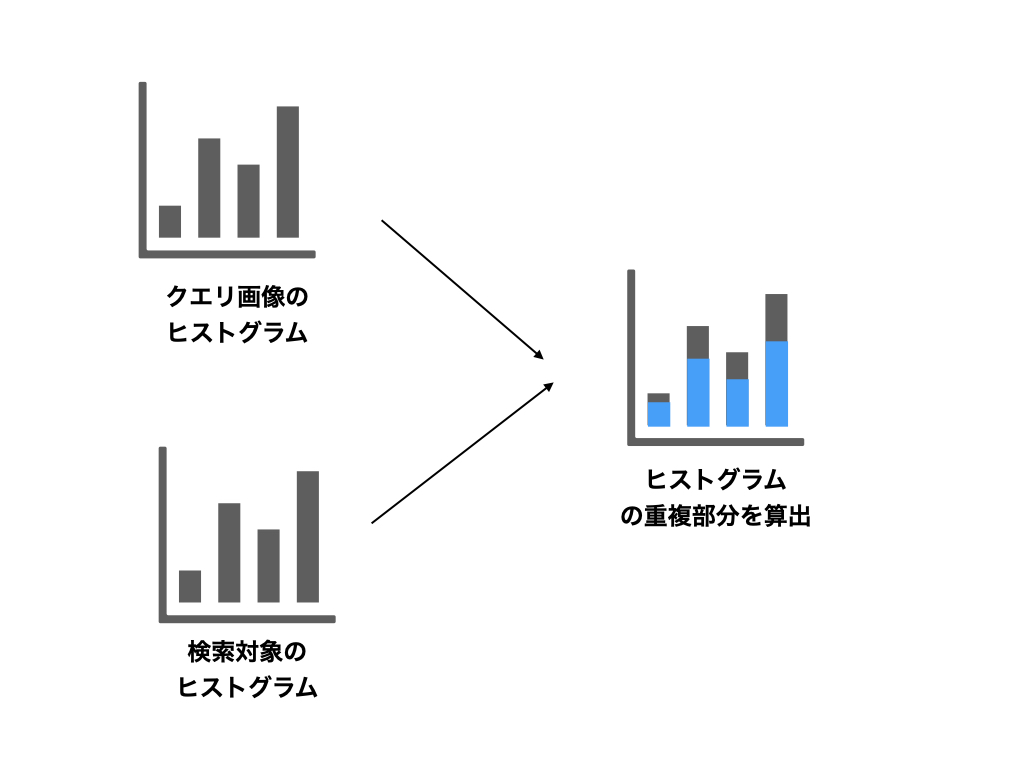
やってることは2つのヒストグラムの各binに対して、小さい方を採用するだけです。 この重複が大きいほど、同様の特徴を多数含む画像と予想されるため、この重複が大きい順に並べてあげれば類似した画像順にランキングされることが期待されます。
ResNet - コサイン類似度
ResNetとコサイン類似度を組み合わせて類似画像を検索することを考えます。
ResNetの部分は選択余地が沢山あり、NNのEmbeddingさえ取れればどんなものでも候補になりえますが、ここでは簡単のため学習済みのResNetを使用します。
今回は画像のサイズが異なっているので、一定のサイズにリサイズしてから画像に対してResNetを適用し、その時のEmbeddingを抽出します。
Embeddingの抽出はこちらの記事を参考にしました。
ResNetで最終層の出力を得る際には、下記のような記述を追加して使用するようですね。
model = models.resnet34(pretrained=True)
model.fc = nn.Identity()
先のケースでElasticseachを使っていたので、こちらの近傍探索もElasticseachを使用したいと思います。 Elasticsearchにはdense vectorというフィールドが使用可能なので、そこにEmbeddingを保存しておきます。 検索時には、dense vectorのフィールドで使用可能なコサイン類似度を使用して、ランキングを作成します。
{ "query" : { "script_score": { "query": {"match_all": {}}, "script": { "source": "cosineSimilarity(params.query_vector, 'embedding') + 1.0", "params": {"query_vector": embedding} } } }
作ったもの
見た目はこんな感じです。

一応、一番上の画像が検索対象の画像で、その下に検索結果が並ぶようになってます。 Embeddingを使う場合には上のgifを見る感じ、同じような画像がランキングの上に来ているので問題なさそうです。
pHashを使ったとき、結果が1件になってしまうのですが、ハミング距離が離れすぎているからでしょう。 今回の画像くらいバラバラの画像だとpHashを使って検索するのは厳しそうです。
また、Akazeを使った検索についてもやってみましたが、あまり良い検索にはなっていませんでした。 画像自体が全く異なるものなので、この辺は仕方ありませんね。 この辺は非常に似通った画像を探す際には効果があるかと思いますので、そういう場面で再チャレンジしてみたいと思います。
なにはともあれ、作ったもの全部入りのリポジトリはこちら。
参考文献
この記事を書くにあたり、下記の文献を非常に参考にさせていただきました。
https://bulbulpaul.com/blog/posts/2016/03/image-similarity/
")
- 作者:原田 達也
- 発売日: 2017/05/25
- メディア: 単行本
感想
色々あって画像検索について調べてみて、せっかくなのでガチャガチャ作ってみた次第です。 全文検索とは異なり、画像検索はあまり文献が多くないなと感じました。 ただ、やり方さえ分かればツールはかなり公開されているので、個人でもなんとかはなりました。 (大変だったけど)
ちゃんとやろうとするとなかなか奥が深いとは思いますが、概要はつかめた気がするので今回はこのへんで。